Amazon EKS Workers
Overview
This service contains Terraform and Packer code to deploy a production-grade EC2 server cluster as workers for Elastic Kubernetes Service (EKS) on AWS.
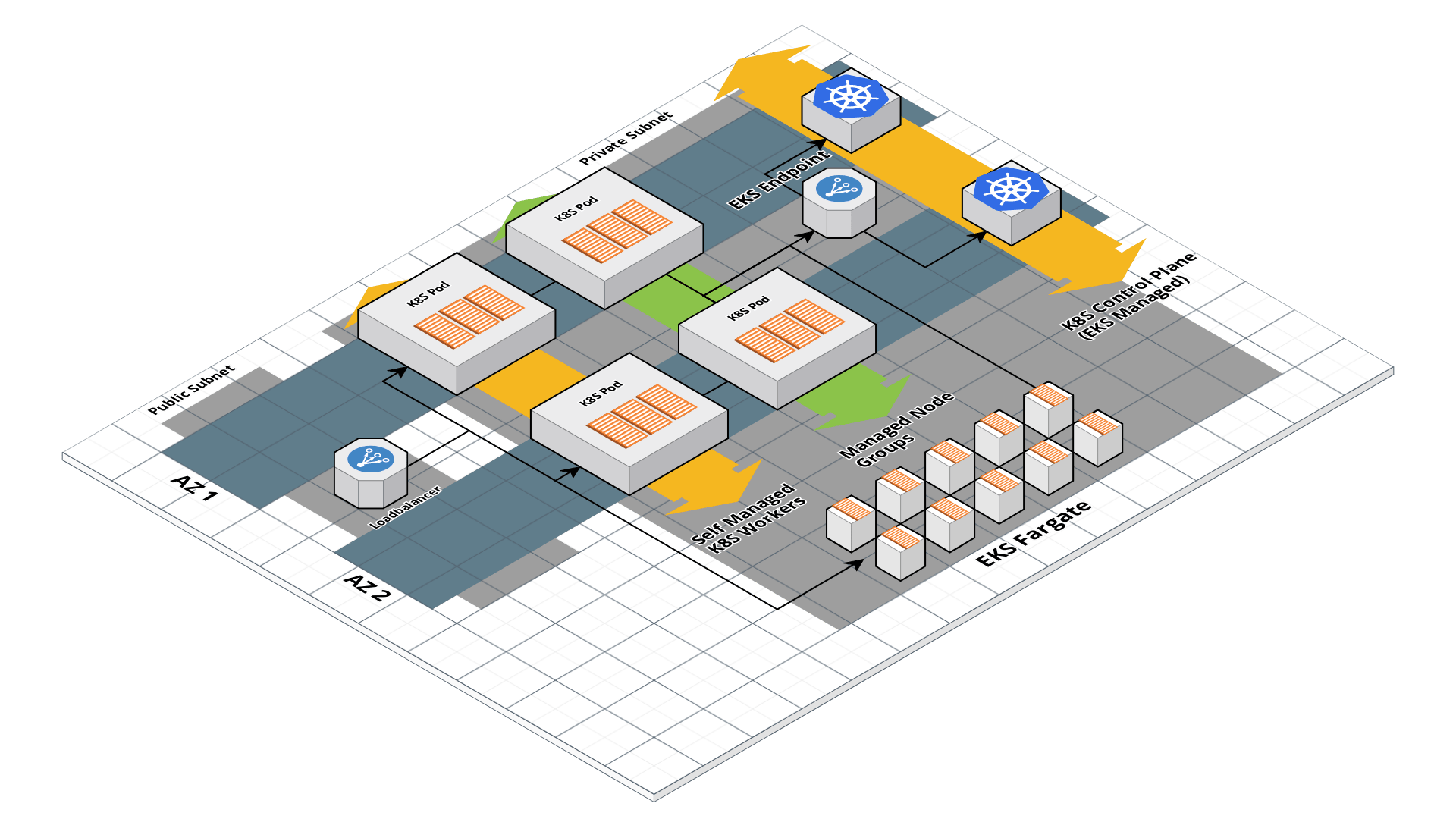 EKS architecture
EKS architecture
Features
-
Deploy self-managed worker nodes in an Auto Scaling Group
-
Deploy managed workers nodes in a Managed Node Group
-
Zero-downtime, rolling deployment for updating worker nodes
-
Auto scaling and auto healing
-
For Nodes:
- Server-hardening with fail2ban, ip-lockdown, auto-update, and more
- Manage SSH access via IAM groups via ssh-grunt
- CloudWatch log aggregation
- CloudWatch metrics and alerts
Learn
This repo is a part of the Gruntwork Service Catalog, a collection of reusable, battle-tested, production ready infrastructure code. If you’ve never used the Service Catalog before, make sure to read How to use the Gruntwork Service Catalog!
Under the hood, this is all implemented using Terraform modules from the Gruntwork terraform-aws-eks repo. If you are a subscriber and don’t have access to this repo, email support@gruntwork.io.
Core concepts
To understand core concepts like what is Kubernetes, the different worker types, how to authenticate to Kubernetes, and more, see the documentation in the terraform-aws-eks repo.
Repo organization
- modules: the main implementation code for this repo, broken down into multiple standalone, orthogonal submodules.
- examples: This folder contains working examples of how to use the submodules.
- test: Automated tests for the modules and examples.
Deploy
Non-production deployment (quick start for learning)
If you just want to try this repo out for experimenting and learning, check out the following resources:
- examples/for-learning-and-testing folder: The
examples/for-learning-and-testingfolder contains standalone sample code optimized for learning, experimenting, and testing (but not direct production usage).
Production deployment
If you want to deploy this repo in production, check out the following resources:
-
examples/for-production folder: The
examples/for-productionfolder contains sample code optimized for direct usage in production. This is code from the Gruntwork Reference Architecture, and it shows you how we build an end-to-end, integrated tech stack on top of the Gruntwork Service Catalog. -
How to deploy a production-grade Kubernetes cluster on AWS: A step-by-step guide for deploying a production-grade EKS cluster on AWS using the code in this repo.
Manage
For information on registering the worker IAM role to the EKS control plane, refer to the IAM Roles and Kubernetes API Access section of the documentation.
For information on how to perform a blue-green deployment of the worker pools, refer to the How do I perform a blue green release to roll out new versions of the module section of the documentation.
For information on how to manage your EKS cluster, including how to deploy Pods on Fargate, how to associate IAM roles to Pod, how to upgrade your EKS cluster, and more, see the documentation in the terraform-aws-eks repo.
Sample Usage
- Terraform
- Terragrunt
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S EKS-WORKERS MODULE
# ------------------------------------------------------------------------------------------------------
module "eks_workers" {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/services/eks-workers?ref=v0.126.2"
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# Configure one or more self-managed Auto Scaling Groups (ASGs) to manage the
# EC2 instances in this cluster. Set to empty object ({}) if you do not wish
# to configure self-managed ASGs.
autoscaling_group_configurations = <any>
# The AMI to run on each instance in the EKS cluster. You can build the AMI
# using the Packer template eks-node-al2.json. One of var.cluster_instance_ami
# or var.cluster_instance_ami_filters is required. Only used if
# var.cluster_instance_ami_filters is null. Set to null if
# cluster_instance_ami_filters is set.
cluster_instance_ami = <string>
# Properties on the AMI that can be used to lookup a prebuilt AMI for use with
# self managed workers. You can build the AMI using the Packer template
# eks-node-al2.json. One of var.cluster_instance_ami or
# var.cluster_instance_ami_filters is required. If both are defined,
# var.cluster_instance_ami_filters will be used. Set to null if
# cluster_instance_ami is set.
cluster_instance_ami_filters = <object(
owners = list(string)
filters = list(object(
name = string
values = list(string)
))
)>
# The name of the EKS cluster. The cluster must exist/already be deployed.
eks_cluster_name = <string>
# Configure one or more Node Groups to manage the EC2 instances in this
# cluster. Set to empty object ({}) if you do not wish to configure managed
# node groups.
managed_node_group_configurations = <any>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of additional security group IDs to be attached on worker groups.
additional_security_groups_for_workers = []
# The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and
# disk space usage) should send notifications.
alarms_sns_topic_arn = []
# The list of CIDR blocks to allow inbound SSH access to the worker groups.
allow_inbound_ssh_from_cidr_blocks = []
# The list of security group IDs to allow inbound SSH access to the worker
# groups.
allow_inbound_ssh_from_security_groups = []
# Where to get the AMI from. Can be 'auto', 'launch_template', or
# 'eks_nodegroup'. WARNING there are limitation on what the value is, check
# the documentation for more information
# https://docs.aws.amazon.com/eks/latest/userguide/launch-templates.html#mng-ami-id-conditions
ami_source = "auto"
# Custom name for the IAM role for the Self-managed workers. When null, a
# default name based on worker_name_prefix will be used. One of
# asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null)
# if asg_iam_role_already_exists is true.
asg_custom_iam_role_name = null
# Default value for enable_detailed_monitoring field of
# autoscaling_group_configurations.
asg_default_enable_detailed_monitoring = true
# Default value for the http_put_response_hop_limit field of
# autoscaling_group_configurations.
asg_default_http_put_response_hop_limit = null
# Default value for the instance_maintenance_policy field of
# autoscaling_group_configurations.
asg_default_instance_maintenance_policy = null
# Default value for the asg_instance_root_volume_encryption field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_encryption will use this value.
asg_default_instance_root_volume_encryption = true
# Default value for the asg_instance_root_volume_iops field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_iops will use this value.
asg_default_instance_root_volume_iops = null
# Default value for the asg_instance_root_volume_size field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_size will use this value.
asg_default_instance_root_volume_size = 40
# Default value for the asg_instance_root_volume_throughput field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_throughput will use this value.
asg_default_instance_root_volume_throughput = null
# Default value for the asg_instance_root_volume_type field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_type will use this value.
asg_default_instance_root_volume_type = "standard"
# Default value for the asg_instance_type field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_type will use this value.
asg_default_instance_type = "t3.medium"
# Default value for the max_pods_allowed field of
# autoscaling_group_configurations. Any map entry that does not specify
# max_pods_allowed will use this value.
asg_default_max_pods_allowed = null
# Default value for the max_size field of autoscaling_group_configurations.
# Any map entry that does not specify max_size will use this value.
asg_default_max_size = 2
# Default value for the min_size field of autoscaling_group_configurations.
# Any map entry that does not specify min_size will use this value.
asg_default_min_size = 1
# Default value for the multi_instance_overrides field of
# autoscaling_group_configurations. Any map entry that does not specify
# multi_instance_overrides will use this value.
asg_default_multi_instance_overrides = []
# Default value for the on_demand_allocation_strategy field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_allocation_strategy will use this value.
asg_default_on_demand_allocation_strategy = null
# Default value for the on_demand_base_capacity field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_base_capacity will use this value.
asg_default_on_demand_base_capacity = null
# Default value for the on_demand_percentage_above_base_capacity field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_percentage_above_base_capacity will use this value.
asg_default_on_demand_percentage_above_base_capacity = null
# Default value for the spot_allocation_strategy field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_allocation_strategy will use this value.
asg_default_spot_allocation_strategy = null
# Default value for the spot_instance_pools field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_instance_pools will use this value.
asg_default_spot_instance_pools = null
# Default value for the spot_max_price field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_max_price will use this value. Set to empty string (default) to mean
# on-demand price.
asg_default_spot_max_price = null
# Default value for the tags field of autoscaling_group_configurations. Any
# map entry that does not specify tags will use this value.
asg_default_tags = []
# Default value for the use_multi_instances_policy field of
# autoscaling_group_configurations. Any map entry that does not specify
# use_multi_instances_policy will use this value.
asg_default_use_multi_instances_policy = false
# Custom name for the IAM instance profile for the Self-managed workers. When
# null, the IAM role name will be used. If var.asg_use_resource_name_prefix is
# true, this will be used as a name prefix.
asg_iam_instance_profile_name = null
# Whether or not the IAM role used for the Self-managed workers already
# exists. When false, this module will create a new IAM role.
asg_iam_role_already_exists = false
# ARN of the IAM role to use if iam_role_already_exists = true. When null,
# uses asg_custom_iam_role_name to lookup the ARN. One of
# asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null)
# if asg_iam_role_already_exists is true.
asg_iam_role_arn = null
# A map of tags to apply to the Security Group of the ASG for the self managed
# worker pool. The key is the tag name and the value is the tag value.
asg_security_group_tags = {}
# When true, all the relevant resources for self managed workers will be set
# to use the name_prefix attribute so that unique names are generated for
# them. This allows those resources to support recreation through
# create_before_destroy lifecycle rules. Set to false if you were using any
# version before 0.65.0 and wish to avoid recreating the entire worker pool on
# your cluster.
asg_use_resource_name_prefix = true
# Boolean value to enable/disable cloudwatch alarms for the EKS Worker ASG.
# Defaults to 'true'.
asg_worker_enable_cloudwatch_alarms = true
# A map of custom tags to apply to the EKS Worker IAM Policies. The key is the
# tag name and the value is the tag value.
asg_worker_iam_policy_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag
# name and the value is the tag value.
asg_worker_iam_role_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Instance Profile. The
# key is the tag name and the value is the tag value.
asg_worker_instance_profile_tags = {}
# Adds additional tags to each ASG that allow a cluster autoscaler to
# auto-discover them. Only used for self-managed workers.
autoscaling_group_include_autoscaler_discovery_tags = true
# Namespace where the AWS Auth Merger is deployed. If configured, the worker
# IAM role will be mapped to the Kubernetes RBAC group for Nodes using a
# ConfigMap in the auth merger namespace.
aws_auth_merger_namespace = null
# Cloud init scripts to run on the EKS worker nodes when it is booting. See
# the part blocks in
# https://www.terraform.io/docs/providers/template/d/cloudinit_config.html for
# syntax. To override the default boot script installed as part of the module,
# use the key `default`.
cloud_init_parts = {}
# The ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for
# encrypting log data. Only used if var.enable_cloudwatch_log_aggregation is
# true.
cloudwatch_log_group_kms_key_id = null
# Name of the CloudWatch Log Group where server system logs are reported to.
# Only used if var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_name = null
# The number of days to retain log events in the log group. Refer to
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days
# for all the valid values. When null, the log events are retained forever.
# Only used if var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_retention_in_days = null
# Tags to apply on the CloudWatch Log Group, encoded as a map where the keys
# are tag keys and values are tag values. Only used if
# var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_tags = null
# Whether or not to associate a public IP address to the instances of the self
# managed ASGs. Will only work if the instances are launched in a public
# subnet.
cluster_instance_associate_public_ip_address = false
# The name of the Key Pair that can be used to SSH to each instance in the EKS
# cluster.
cluster_instance_keypair_name = null
# A map of unique identifiers to egress security group rules to attach to the
# worker groups.
custom_egress_security_group_rules = {}
# A map of unique identifiers to ingress security group rules to attach to the
# worker groups.
custom_ingress_security_group_rules = {}
# Parameters for the worker cpu usage widget to output for use in a CloudWatch
# dashboard.
dashboard_cpu_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the worker disk usage widget to output for use in a
# CloudWatch dashboard.
dashboard_disk_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the worker memory usage widget to output for use in a
# CloudWatch dashboard.
dashboard_memory_usage_widget_parameters = {"height":6,"period":60,"width":8}
# A map of default tags to apply to all supported resources in this module.
# These tags will be merged with any other resource specific tags. The key is
# the tag name and the value is the tag value.
default_tags = {}
# Set to true to enable several basic CloudWatch alarms around CPU usage,
# memory usage, and disk space usage. If set to true, make sure to specify SNS
# topics to send notifications to using var.alarms_sns_topic_arn.
enable_cloudwatch_alarms = true
# Set to true to send logs to CloudWatch. This is useful in combination with
# https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/logs/cloudwatch-log-aggregation-scripts
# to do log aggregation in CloudWatch. Note that this is only recommended for
# aggregating system level logs from the server instances. Container logs
# should be managed through fluent-bit deployed with eks-core-services.
enable_cloudwatch_log_aggregation = false
# Set to true to add IAM permissions to send custom metrics to CloudWatch.
# This is useful in combination with
# https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/agents/cloudwatch-agent
# to get memory and disk metrics in CloudWatch for your Bastion host.
enable_cloudwatch_metrics = true
# Enable fail2ban to block brute force log in attempts. Defaults to true.
enable_fail2ban = true
# If you are using ssh-grunt and your IAM users / groups are defined in a
# separate AWS account, you can use this variable to specify the ARN of an IAM
# role that ssh-grunt can assume to retrieve IAM group and public SSH key info
# from that account. To omit this variable, set it to an empty string (do NOT
# use null, or Terraform will complain).
external_account_ssh_grunt_role_arn = ""
# The period, in seconds, over which to measure the CPU utilization percentage
# for the ASG.
high_worker_cpu_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster CPU utilization
# percentage above this threshold.
high_worker_cpu_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_cpu_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the root disk utilization
# percentage for the ASG.
high_worker_disk_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster root disk utilization
# percentage above this threshold.
high_worker_disk_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_disk_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the Memory utilization
# percentage for the ASG.
high_worker_memory_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster Memory utilization
# percentage above this threshold.
high_worker_memory_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_memory_utilization_treat_missing_data = "missing"
# Custom name for the IAM role for the Managed Node Groups. When null, a
# default name based on worker_name_prefix will be used. One of
# managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn
# is required (must be non-null) if managed_node_group_iam_role_already_exists
# is true.
managed_node_group_custom_iam_role_name = null
# Whether or not the IAM role used for the Managed Node Group workers already
# exists. When false, this module will create a new IAM role.
managed_node_group_iam_role_already_exists = false
# ARN of the IAM role to use if iam_role_already_exists = true. When null,
# uses managed_node_group_custom_iam_role_name to lookup the ARN. One of
# managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn
# is required (must be non-null) if managed_node_group_iam_role_already_exists
# is true.
managed_node_group_iam_role_arn = null
# Default value for capacity_type field of managed_node_group_configurations.
node_group_default_capacity_type = "ON_DEMAND"
# Default value for desired_size field of managed_node_group_configurations.
node_group_default_desired_size = 1
# Default value for enable_detailed_monitoring field of
# managed_node_group_configurations.
node_group_default_enable_detailed_monitoring = true
# Default value for http_put_response_hop_limit field of
# managed_node_group_configurations. Any map entry that does not specify
# http_put_response_hop_limit will use this value.
node_group_default_http_put_response_hop_limit = null
# Default value for the instance_root_volume_encryption field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_encryption = true
# Default voume name for the instance_root_volume_name field in
# managed_node_group_configurations.
node_group_default_instance_root_volume_name = "/dev/xvda"
# Default value for the instance_root_volume_size field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_size = 40
# Default value for the instance_root_volume_type field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_type = "gp3"
# Default value for instance_types field of managed_node_group_configurations.
node_group_default_instance_types = null
# Default value for labels field of managed_node_group_configurations. Unlike
# common_labels which will always be merged in, these labels are only used if
# the labels field is omitted from the configuration.
node_group_default_labels = {}
# Default value for the max_pods_allowed field of
# managed_node_group_configurations. Any map entry that does not specify
# max_pods_allowed will use this value.
node_group_default_max_pods_allowed = null
# Default value for max_size field of managed_node_group_configurations.
node_group_default_max_size = 1
# Default value for min_size field of managed_node_group_configurations.
node_group_default_min_size = 1
# Default value for subnet_ids field of managed_node_group_configurations.
node_group_default_subnet_ids = null
# Default value for tags field of managed_node_group_configurations. Unlike
# common_tags which will always be merged in, these tags are only used if the
# tags field is omitted from the configuration.
node_group_default_tags = {}
# Default value for taint field of node_group_configurations. These taints are
# only used if the taint field is omitted from the configuration.
node_group_default_taints = []
# The instance type to configure in the launch template. This value will be
# used when the instance_types field is set to null (NOT omitted, in which
# case var.node_group_default_instance_types will be used).
node_group_launch_template_instance_type = null
# Tags assigned to a node group are mirrored to the underlaying autoscaling
# group by default. If you want to disable this behaviour, set this flag to
# false. Note that this assumes that there is a one-to-one mappping between
# ASGs and Node Groups. If there is more than one ASG mapped to the Node
# Group, then this will only apply the tags on the first one. Due to a
# limitation in Terraform for_each where it can not depend on dynamic data, it
# is currently not possible in the module to map the tags to all ASGs. If you
# wish to apply the tags to all underlying ASGs, then it is recommended to
# call the aws_autoscaling_group_tag resource in a separate terraform state
# file outside of this module, or use a two-stage apply process.
node_group_mirror_tags_to_asg = true
# The names of the node groups. When null, this value is automatically
# calculated from the managed_node_group_configurations map. This variable
# must be set if any of the values of the managed_node_group_configurations
# map depends on a resource that is not available at plan time to work around
# terraform limitations with for_each.
node_group_names = null
# A map of tags to apply to the Security Group of the ASG for the managed node
# group pool. The key is the tag name and the value is the tag value.
node_group_security_group_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag
# name and the value is the tag value.
node_group_worker_iam_role_tags = {}
# If you are using ssh-grunt, this is the name of the IAM group from which
# users will be allowed to SSH to the EKS workers. To omit this variable, set
# it to an empty string (do NOT use null, or Terraform will complain).
ssh_grunt_iam_group = "ssh-grunt-users"
# If you are using ssh-grunt, this is the name of the IAM group from which
# users will be allowed to SSH to the EKS workers with sudo permissions. To
# omit this variable, set it to an empty string (do NOT use null, or Terraform
# will complain).
ssh_grunt_iam_group_sudo = "ssh-grunt-sudo-users"
# The tenancy of the servers in the self-managed worker ASG. Must be one of:
# default, dedicated, or host.
tenancy = "default"
# If this variable is set to true, then use an exec-based plugin to
# authenticate and fetch tokens for EKS. This is useful because EKS clusters
# use short-lived authentication tokens that can expire in the middle of an
# 'apply' or 'destroy', and since the native Kubernetes provider in Terraform
# doesn't have a way to fetch up-to-date tokens, we recommend using an
# exec-based provider as a workaround. Use the use_kubergrunt_to_fetch_token
# input variable to control whether kubergrunt or aws is used to fetch tokens.
use_exec_plugin_for_auth = true
# Set this variable to true to enable the use of Instance Metadata Service
# Version 1 in this module's aws_launch_template. Note that while IMDsv2 is
# preferred due to its special security hardening, we allow this in order to
# support the use case of AMIs built outside of these modules that depend on
# IMDSv1.
use_imdsv1 = false
# EKS clusters use short-lived authentication tokens that can expire in the
# middle of an 'apply' or 'destroy'. To avoid this issue, we use an exec-based
# plugin to fetch an up-to-date token. If this variable is set to true, we'll
# use kubergrunt to fetch the token (in which case, kubergrunt must be
# installed and on PATH); if this variable is set to false, we'll use the aws
# CLI to fetch the token (in which case, aws must be installed and on PATH).
# Note this functionality is only enabled if use_exec_plugin_for_auth is set
# to true.
use_kubergrunt_to_fetch_token = true
# When true, all IAM policies will be managed as dedicated policies rather
# than inline policies attached to the IAM roles. Dedicated managed policies
# are friendlier to automated policy checkers, which may scan a single
# resource for findings. As such, it is important to avoid inline policies
# when targeting compliance with various security standards.
use_managed_iam_policies = true
# When true, assumes prefix delegation mode is in use for the AWS VPC CNI
# component of the EKS cluster when computing max pods allowed on the node. In
# prefix delegation mode, each ENI will be allocated 16 IP addresses (/28)
# instead of 1, allowing you to pack more Pods per node.
use_prefix_mode_to_calculate_max_pods = false
# Name of the IAM role to Kubernetes RBAC group mapping ConfigMap. Only used
# if aws_auth_merger_namespace is not null.
worker_k8s_role_mapping_name = "eks-cluster-worker-iam-mapping"
# Prefix EKS worker resource names with this string. When you have multiple
# worker groups for the cluster, you can use this to namespace the resources.
# Defaults to empty string so that resource names are not excessively long by
# default.
worker_name_prefix = ""
}
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S EKS-WORKERS MODULE
# ------------------------------------------------------------------------------------------------------
terraform {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/services/eks-workers?ref=v0.126.2"
}
inputs = {
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# Configure one or more self-managed Auto Scaling Groups (ASGs) to manage the
# EC2 instances in this cluster. Set to empty object ({}) if you do not wish
# to configure self-managed ASGs.
autoscaling_group_configurations = <any>
# The AMI to run on each instance in the EKS cluster. You can build the AMI
# using the Packer template eks-node-al2.json. One of var.cluster_instance_ami
# or var.cluster_instance_ami_filters is required. Only used if
# var.cluster_instance_ami_filters is null. Set to null if
# cluster_instance_ami_filters is set.
cluster_instance_ami = <string>
# Properties on the AMI that can be used to lookup a prebuilt AMI for use with
# self managed workers. You can build the AMI using the Packer template
# eks-node-al2.json. One of var.cluster_instance_ami or
# var.cluster_instance_ami_filters is required. If both are defined,
# var.cluster_instance_ami_filters will be used. Set to null if
# cluster_instance_ami is set.
cluster_instance_ami_filters = <object(
owners = list(string)
filters = list(object(
name = string
values = list(string)
))
)>
# The name of the EKS cluster. The cluster must exist/already be deployed.
eks_cluster_name = <string>
# Configure one or more Node Groups to manage the EC2 instances in this
# cluster. Set to empty object ({}) if you do not wish to configure managed
# node groups.
managed_node_group_configurations = <any>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of additional security group IDs to be attached on worker groups.
additional_security_groups_for_workers = []
# The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and
# disk space usage) should send notifications.
alarms_sns_topic_arn = []
# The list of CIDR blocks to allow inbound SSH access to the worker groups.
allow_inbound_ssh_from_cidr_blocks = []
# The list of security group IDs to allow inbound SSH access to the worker
# groups.
allow_inbound_ssh_from_security_groups = []
# Where to get the AMI from. Can be 'auto', 'launch_template', or
# 'eks_nodegroup'. WARNING there are limitation on what the value is, check
# the documentation for more information
# https://docs.aws.amazon.com/eks/latest/userguide/launch-templates.html#mng-ami-id-conditions
ami_source = "auto"
# Custom name for the IAM role for the Self-managed workers. When null, a
# default name based on worker_name_prefix will be used. One of
# asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null)
# if asg_iam_role_already_exists is true.
asg_custom_iam_role_name = null
# Default value for enable_detailed_monitoring field of
# autoscaling_group_configurations.
asg_default_enable_detailed_monitoring = true
# Default value for the http_put_response_hop_limit field of
# autoscaling_group_configurations.
asg_default_http_put_response_hop_limit = null
# Default value for the instance_maintenance_policy field of
# autoscaling_group_configurations.
asg_default_instance_maintenance_policy = null
# Default value for the asg_instance_root_volume_encryption field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_encryption will use this value.
asg_default_instance_root_volume_encryption = true
# Default value for the asg_instance_root_volume_iops field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_iops will use this value.
asg_default_instance_root_volume_iops = null
# Default value for the asg_instance_root_volume_size field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_size will use this value.
asg_default_instance_root_volume_size = 40
# Default value for the asg_instance_root_volume_throughput field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_throughput will use this value.
asg_default_instance_root_volume_throughput = null
# Default value for the asg_instance_root_volume_type field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_root_volume_type will use this value.
asg_default_instance_root_volume_type = "standard"
# Default value for the asg_instance_type field of
# autoscaling_group_configurations. Any map entry that does not specify
# asg_instance_type will use this value.
asg_default_instance_type = "t3.medium"
# Default value for the max_pods_allowed field of
# autoscaling_group_configurations. Any map entry that does not specify
# max_pods_allowed will use this value.
asg_default_max_pods_allowed = null
# Default value for the max_size field of autoscaling_group_configurations.
# Any map entry that does not specify max_size will use this value.
asg_default_max_size = 2
# Default value for the min_size field of autoscaling_group_configurations.
# Any map entry that does not specify min_size will use this value.
asg_default_min_size = 1
# Default value for the multi_instance_overrides field of
# autoscaling_group_configurations. Any map entry that does not specify
# multi_instance_overrides will use this value.
asg_default_multi_instance_overrides = []
# Default value for the on_demand_allocation_strategy field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_allocation_strategy will use this value.
asg_default_on_demand_allocation_strategy = null
# Default value for the on_demand_base_capacity field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_base_capacity will use this value.
asg_default_on_demand_base_capacity = null
# Default value for the on_demand_percentage_above_base_capacity field of
# autoscaling_group_configurations. Any map entry that does not specify
# on_demand_percentage_above_base_capacity will use this value.
asg_default_on_demand_percentage_above_base_capacity = null
# Default value for the spot_allocation_strategy field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_allocation_strategy will use this value.
asg_default_spot_allocation_strategy = null
# Default value for the spot_instance_pools field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_instance_pools will use this value.
asg_default_spot_instance_pools = null
# Default value for the spot_max_price field of
# autoscaling_group_configurations. Any map entry that does not specify
# spot_max_price will use this value. Set to empty string (default) to mean
# on-demand price.
asg_default_spot_max_price = null
# Default value for the tags field of autoscaling_group_configurations. Any
# map entry that does not specify tags will use this value.
asg_default_tags = []
# Default value for the use_multi_instances_policy field of
# autoscaling_group_configurations. Any map entry that does not specify
# use_multi_instances_policy will use this value.
asg_default_use_multi_instances_policy = false
# Custom name for the IAM instance profile for the Self-managed workers. When
# null, the IAM role name will be used. If var.asg_use_resource_name_prefix is
# true, this will be used as a name prefix.
asg_iam_instance_profile_name = null
# Whether or not the IAM role used for the Self-managed workers already
# exists. When false, this module will create a new IAM role.
asg_iam_role_already_exists = false
# ARN of the IAM role to use if iam_role_already_exists = true. When null,
# uses asg_custom_iam_role_name to lookup the ARN. One of
# asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null)
# if asg_iam_role_already_exists is true.
asg_iam_role_arn = null
# A map of tags to apply to the Security Group of the ASG for the self managed
# worker pool. The key is the tag name and the value is the tag value.
asg_security_group_tags = {}
# When true, all the relevant resources for self managed workers will be set
# to use the name_prefix attribute so that unique names are generated for
# them. This allows those resources to support recreation through
# create_before_destroy lifecycle rules. Set to false if you were using any
# version before 0.65.0 and wish to avoid recreating the entire worker pool on
# your cluster.
asg_use_resource_name_prefix = true
# Boolean value to enable/disable cloudwatch alarms for the EKS Worker ASG.
# Defaults to 'true'.
asg_worker_enable_cloudwatch_alarms = true
# A map of custom tags to apply to the EKS Worker IAM Policies. The key is the
# tag name and the value is the tag value.
asg_worker_iam_policy_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag
# name and the value is the tag value.
asg_worker_iam_role_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Instance Profile. The
# key is the tag name and the value is the tag value.
asg_worker_instance_profile_tags = {}
# Adds additional tags to each ASG that allow a cluster autoscaler to
# auto-discover them. Only used for self-managed workers.
autoscaling_group_include_autoscaler_discovery_tags = true
# Namespace where the AWS Auth Merger is deployed. If configured, the worker
# IAM role will be mapped to the Kubernetes RBAC group for Nodes using a
# ConfigMap in the auth merger namespace.
aws_auth_merger_namespace = null
# Cloud init scripts to run on the EKS worker nodes when it is booting. See
# the part blocks in
# https://www.terraform.io/docs/providers/template/d/cloudinit_config.html for
# syntax. To override the default boot script installed as part of the module,
# use the key `default`.
cloud_init_parts = {}
# The ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for
# encrypting log data. Only used if var.enable_cloudwatch_log_aggregation is
# true.
cloudwatch_log_group_kms_key_id = null
# Name of the CloudWatch Log Group where server system logs are reported to.
# Only used if var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_name = null
# The number of days to retain log events in the log group. Refer to
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days
# for all the valid values. When null, the log events are retained forever.
# Only used if var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_retention_in_days = null
# Tags to apply on the CloudWatch Log Group, encoded as a map where the keys
# are tag keys and values are tag values. Only used if
# var.enable_cloudwatch_log_aggregation is true.
cloudwatch_log_group_tags = null
# Whether or not to associate a public IP address to the instances of the self
# managed ASGs. Will only work if the instances are launched in a public
# subnet.
cluster_instance_associate_public_ip_address = false
# The name of the Key Pair that can be used to SSH to each instance in the EKS
# cluster.
cluster_instance_keypair_name = null
# A map of unique identifiers to egress security group rules to attach to the
# worker groups.
custom_egress_security_group_rules = {}
# A map of unique identifiers to ingress security group rules to attach to the
# worker groups.
custom_ingress_security_group_rules = {}
# Parameters for the worker cpu usage widget to output for use in a CloudWatch
# dashboard.
dashboard_cpu_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the worker disk usage widget to output for use in a
# CloudWatch dashboard.
dashboard_disk_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the worker memory usage widget to output for use in a
# CloudWatch dashboard.
dashboard_memory_usage_widget_parameters = {"height":6,"period":60,"width":8}
# A map of default tags to apply to all supported resources in this module.
# These tags will be merged with any other resource specific tags. The key is
# the tag name and the value is the tag value.
default_tags = {}
# Set to true to enable several basic CloudWatch alarms around CPU usage,
# memory usage, and disk space usage. If set to true, make sure to specify SNS
# topics to send notifications to using var.alarms_sns_topic_arn.
enable_cloudwatch_alarms = true
# Set to true to send logs to CloudWatch. This is useful in combination with
# https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/logs/cloudwatch-log-aggregation-scripts
# to do log aggregation in CloudWatch. Note that this is only recommended for
# aggregating system level logs from the server instances. Container logs
# should be managed through fluent-bit deployed with eks-core-services.
enable_cloudwatch_log_aggregation = false
# Set to true to add IAM permissions to send custom metrics to CloudWatch.
# This is useful in combination with
# https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/agents/cloudwatch-agent
# to get memory and disk metrics in CloudWatch for your Bastion host.
enable_cloudwatch_metrics = true
# Enable fail2ban to block brute force log in attempts. Defaults to true.
enable_fail2ban = true
# If you are using ssh-grunt and your IAM users / groups are defined in a
# separate AWS account, you can use this variable to specify the ARN of an IAM
# role that ssh-grunt can assume to retrieve IAM group and public SSH key info
# from that account. To omit this variable, set it to an empty string (do NOT
# use null, or Terraform will complain).
external_account_ssh_grunt_role_arn = ""
# The period, in seconds, over which to measure the CPU utilization percentage
# for the ASG.
high_worker_cpu_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster CPU utilization
# percentage above this threshold.
high_worker_cpu_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_cpu_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the root disk utilization
# percentage for the ASG.
high_worker_disk_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster root disk utilization
# percentage above this threshold.
high_worker_disk_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_disk_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the Memory utilization
# percentage for the ASG.
high_worker_memory_utilization_period = 60
# Trigger an alarm if the ASG has an average cluster Memory utilization
# percentage above this threshold.
high_worker_memory_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_worker_memory_utilization_treat_missing_data = "missing"
# Custom name for the IAM role for the Managed Node Groups. When null, a
# default name based on worker_name_prefix will be used. One of
# managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn
# is required (must be non-null) if managed_node_group_iam_role_already_exists
# is true.
managed_node_group_custom_iam_role_name = null
# Whether or not the IAM role used for the Managed Node Group workers already
# exists. When false, this module will create a new IAM role.
managed_node_group_iam_role_already_exists = false
# ARN of the IAM role to use if iam_role_already_exists = true. When null,
# uses managed_node_group_custom_iam_role_name to lookup the ARN. One of
# managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn
# is required (must be non-null) if managed_node_group_iam_role_already_exists
# is true.
managed_node_group_iam_role_arn = null
# Default value for capacity_type field of managed_node_group_configurations.
node_group_default_capacity_type = "ON_DEMAND"
# Default value for desired_size field of managed_node_group_configurations.
node_group_default_desired_size = 1
# Default value for enable_detailed_monitoring field of
# managed_node_group_configurations.
node_group_default_enable_detailed_monitoring = true
# Default value for http_put_response_hop_limit field of
# managed_node_group_configurations. Any map entry that does not specify
# http_put_response_hop_limit will use this value.
node_group_default_http_put_response_hop_limit = null
# Default value for the instance_root_volume_encryption field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_encryption = true
# Default voume name for the instance_root_volume_name field in
# managed_node_group_configurations.
node_group_default_instance_root_volume_name = "/dev/xvda"
# Default value for the instance_root_volume_size field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_size = 40
# Default value for the instance_root_volume_type field of
# managed_node_group_configurations.
node_group_default_instance_root_volume_type = "gp3"
# Default value for instance_types field of managed_node_group_configurations.
node_group_default_instance_types = null
# Default value for labels field of managed_node_group_configurations. Unlike
# common_labels which will always be merged in, these labels are only used if
# the labels field is omitted from the configuration.
node_group_default_labels = {}
# Default value for the max_pods_allowed field of
# managed_node_group_configurations. Any map entry that does not specify
# max_pods_allowed will use this value.
node_group_default_max_pods_allowed = null
# Default value for max_size field of managed_node_group_configurations.
node_group_default_max_size = 1
# Default value for min_size field of managed_node_group_configurations.
node_group_default_min_size = 1
# Default value for subnet_ids field of managed_node_group_configurations.
node_group_default_subnet_ids = null
# Default value for tags field of managed_node_group_configurations. Unlike
# common_tags which will always be merged in, these tags are only used if the
# tags field is omitted from the configuration.
node_group_default_tags = {}
# Default value for taint field of node_group_configurations. These taints are
# only used if the taint field is omitted from the configuration.
node_group_default_taints = []
# The instance type to configure in the launch template. This value will be
# used when the instance_types field is set to null (NOT omitted, in which
# case var.node_group_default_instance_types will be used).
node_group_launch_template_instance_type = null
# Tags assigned to a node group are mirrored to the underlaying autoscaling
# group by default. If you want to disable this behaviour, set this flag to
# false. Note that this assumes that there is a one-to-one mappping between
# ASGs and Node Groups. If there is more than one ASG mapped to the Node
# Group, then this will only apply the tags on the first one. Due to a
# limitation in Terraform for_each where it can not depend on dynamic data, it
# is currently not possible in the module to map the tags to all ASGs. If you
# wish to apply the tags to all underlying ASGs, then it is recommended to
# call the aws_autoscaling_group_tag resource in a separate terraform state
# file outside of this module, or use a two-stage apply process.
node_group_mirror_tags_to_asg = true
# The names of the node groups. When null, this value is automatically
# calculated from the managed_node_group_configurations map. This variable
# must be set if any of the values of the managed_node_group_configurations
# map depends on a resource that is not available at plan time to work around
# terraform limitations with for_each.
node_group_names = null
# A map of tags to apply to the Security Group of the ASG for the managed node
# group pool. The key is the tag name and the value is the tag value.
node_group_security_group_tags = {}
# A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag
# name and the value is the tag value.
node_group_worker_iam_role_tags = {}
# If you are using ssh-grunt, this is the name of the IAM group from which
# users will be allowed to SSH to the EKS workers. To omit this variable, set
# it to an empty string (do NOT use null, or Terraform will complain).
ssh_grunt_iam_group = "ssh-grunt-users"
# If you are using ssh-grunt, this is the name of the IAM group from which
# users will be allowed to SSH to the EKS workers with sudo permissions. To
# omit this variable, set it to an empty string (do NOT use null, or Terraform
# will complain).
ssh_grunt_iam_group_sudo = "ssh-grunt-sudo-users"
# The tenancy of the servers in the self-managed worker ASG. Must be one of:
# default, dedicated, or host.
tenancy = "default"
# If this variable is set to true, then use an exec-based plugin to
# authenticate and fetch tokens for EKS. This is useful because EKS clusters
# use short-lived authentication tokens that can expire in the middle of an
# 'apply' or 'destroy', and since the native Kubernetes provider in Terraform
# doesn't have a way to fetch up-to-date tokens, we recommend using an
# exec-based provider as a workaround. Use the use_kubergrunt_to_fetch_token
# input variable to control whether kubergrunt or aws is used to fetch tokens.
use_exec_plugin_for_auth = true
# Set this variable to true to enable the use of Instance Metadata Service
# Version 1 in this module's aws_launch_template. Note that while IMDsv2 is
# preferred due to its special security hardening, we allow this in order to
# support the use case of AMIs built outside of these modules that depend on
# IMDSv1.
use_imdsv1 = false
# EKS clusters use short-lived authentication tokens that can expire in the
# middle of an 'apply' or 'destroy'. To avoid this issue, we use an exec-based
# plugin to fetch an up-to-date token. If this variable is set to true, we'll
# use kubergrunt to fetch the token (in which case, kubergrunt must be
# installed and on PATH); if this variable is set to false, we'll use the aws
# CLI to fetch the token (in which case, aws must be installed and on PATH).
# Note this functionality is only enabled if use_exec_plugin_for_auth is set
# to true.
use_kubergrunt_to_fetch_token = true
# When true, all IAM policies will be managed as dedicated policies rather
# than inline policies attached to the IAM roles. Dedicated managed policies
# are friendlier to automated policy checkers, which may scan a single
# resource for findings. As such, it is important to avoid inline policies
# when targeting compliance with various security standards.
use_managed_iam_policies = true
# When true, assumes prefix delegation mode is in use for the AWS VPC CNI
# component of the EKS cluster when computing max pods allowed on the node. In
# prefix delegation mode, each ENI will be allocated 16 IP addresses (/28)
# instead of 1, allowing you to pack more Pods per node.
use_prefix_mode_to_calculate_max_pods = false
# Name of the IAM role to Kubernetes RBAC group mapping ConfigMap. Only used
# if aws_auth_merger_namespace is not null.
worker_k8s_role_mapping_name = "eks-cluster-worker-iam-mapping"
# Prefix EKS worker resource names with this string. When you have multiple
# worker groups for the cluster, you can use this to namespace the resources.
# Defaults to empty string so that resource names are not excessively long by
# default.
worker_name_prefix = ""
}
Reference
- Inputs
- Outputs
Required
Configure one or more self-managed Auto Scaling Groups (ASGs) to manage the EC2 instances in this cluster. Set to empty object ({}) if you do not wish to configure self-managed ASGs.
Any types represent complex values of variable type. For details, please consult `variables.tf` in the source repo.
Details
Each configuration must be keyed by a unique string that will be used as a suffix for the ASG name. The values
support the following attributes:
REQUIRED (must be provided for every entry):
- subnet_ids list(string) : A list of the subnets into which the EKS Cluster's worker nodes will be launched.
These should usually be all private subnets and include one in each AWS Availability
Zone. NOTE: If using a cluster autoscaler, each ASG may only belong to a single
availability zone.
OPTIONAL (defaults to value of corresponding module input):
- min_size number : (Defaults to value from var.asg_default_min_size) The minimum number of
EC2 Instances representing workers launchable for this EKS Cluster.
Useful for auto-scaling limits.
- max_size number : (Defaults to value from var.asg_default_max_size) The maximum number of
EC2 Instances representing workers that must be running for this EKS
Cluster. We recommend making this at least twice the min_size, even if
you don't plan on scaling the cluster up and down, as the extra capacity
will be used to deploy updates to the cluster.
- asg_instance_type string : (Defaults to value from var.asg_default_instance_type) The type of
instances to use for the ASG (e.g., t2.medium).
- max_pods_allowed number : (Defaults to value from var.asg_default_max_pods_allowed) The
maximum number of Pods allowed to be scheduled on the node. When null,
the max will be automatically calculated based on the availability of
total IP addresses to the instance type.
- asg_instance_root_volume_size number : (Defaults to value from var.asg_default_instance_root_volume_size) The root volume size of
instances to use for the ASG in GB (e.g., 40).
- asg_instance_root_volume_type string : (Defaults to value from var.asg_default_instance_root_volume_type) The root volume type of
instances to use for the ASG (e.g., "standard").
- asg_instance_root_volume_iops number : (Defaults to value from var.asg_default_instance_root_volume_iops) The root volume iops of
instances to use for the ASG (e.g., 200).
- asg_instance_root_volume_throughput number : (Defaults to value from var.asg_default_instance_root_volume_throughput) The root volume throughput in MiBPS of
instances to use for the ASG (e.g., 125).
- asg_instance_root_volume_encryption bool : (Defaults to value from var.asg_default_instance_root_volume_encryption)
Whether or not to enable root volume encryption for instances of the ASG.
- tags list(object[Tag]) : (Defaults to value from var.asg_default_tags) Custom tags to apply to the
EC2 Instances in this ASG. Refer to structure definition below for the
object type of each entry in the list.
- enable_detailed_monitoring bool : (Defaults to value from
var.asg_default_enable_detailed_monitoring) Whether to enable
detailed monitoring on the EC2 instances that comprise the ASG.
- use_multi_instances_policy bool : (Defaults to value from var.asg_default_use_multi_instances_policy)
Whether or not to use a multi_instances_policy for the ASG.
- multi_instance_overrides list(MultiInstanceOverride) : (Defaults to value from var.asg_default_multi_instance_overrides)
List of multi instance overrides to apply. Each element in the list is
an object that specifies the instance_type to use for the override, and
the weighted_capacity.
- on_demand_allocation_strategy string : (Defaults to value from var.asg_default_on_demand_allocation_strategy)
When using a multi_instances_policy the strategy to use when launching on-demand instances. Valid values: prioritized.
- on_demand_base_capacity number : (Defaults to value from var.asg_default_on_demand_base_capacity)
When using a multi_instances_policy the absolute minimum amount of desired capacity that must be fulfilled by on-demand instances.
- on_demand_percentage_above_base_capacity number : (Defaults to value from var.asg_default_on_demand_percentage_above_base_capacity)
When using a multi_instances_policy the percentage split between on-demand and Spot instances above the base on-demand capacity.
- spot_allocation_strategy string : (Defaults to value from var.asg_default_spot_allocation_strategy)
When using a multi_instances_policy how to allocate capacity across the Spot pools. Valid values: lowest-price, capacity-optimized.
- spot_instance_pools number : (Defaults to value from var.asg_default_spot_instance_pools)
When using a multi_instances_policy the Number of Spot pools per availability zone to allocate capacity.
EC2 Auto Scaling selects the cheapest Spot pools and evenly allocates Spot capacity across the number of Spot pools that you specify.
- spot_max_price string : (Defaults to value from var.asg_default_spot_max_price, an empty string which means the on-demand price.)
When using a multi_instances_policy the maximum price per unit hour that the user is willing to pay for the Spot instances.
- eks_kubelet_extra_args string : Extra args to pass to the kubelet process on node boot.
- eks_bootstrap_script_options string : Extra option args to pass to the bootstrap.sh script. This will be
passed through directly to the bootstrap script.
- cloud_init_parts map(string) : (Defaults to value from var.cloud_init_parts)
Per-ASG cloud init scripts to run at boot time on the node. See var.cloud_init_parts for accepted keys.
- http_put_response_hop_limit number : (Defaults to value from var.asg_default_http_put_response_hop_limit) The
desired HTTP PUT response hop limit for instance metadata requests.
- instance_maintenance_policy object(Health_Percentage)
Structure of Health_Percentage object:
- min_healthy_percentage number : Min healthy percentage forthe intance maintenance policy
- max_healthy_percentage number : Max healthy percentage for the intance maintenance policy
Structure of Tag object:
- key string : The key for the tag to apply to the instance.
- value string : The value for the tag to apply to the instance.
- propagate_at_launch bool : Whether or not the tags should be propagated to the instance at launch time.
Example:
autoscaling_group_configurations = {
"asg1" = {
asg_instance_type = "t2.medium"
subnet_ids = [data.terraform_remote_state.vpc.outputs.private_app_subnet_ids[0]]
},
"asg2" = {
max_size = 3
asg_instance_type = "t2.large"
subnet_ids = [data.terraform_remote_state.vpc.outputs.private_app_subnet_ids[1]]
tags = [{
key = "size"
value = "large"
propagate_at_launch = true
}]
}
}
cluster_instance_amistringThe AMI to run on each instance in the EKS cluster. You can build the AMI using the Packer template eks-node-al2.json. One of cluster_instance_ami or cluster_instance_ami_filters is required. Only used if cluster_instance_ami_filters is null. Set to null if cluster_instance_ami_filters is set.
cluster_instance_ami_filtersobject(…)Properties on the AMI that can be used to lookup a prebuilt AMI for use with self managed workers. You can build the AMI using the Packer template eks-node-al2.json. One of cluster_instance_ami or cluster_instance_ami_filters is required. If both are defined, cluster_instance_ami_filters will be used. Set to null if cluster_instance_ami is set.
object({
# List of owners to limit the search. Set to null if you do not wish to limit the search by AMI owners.
owners = list(string)
# Name/Value pairs to filter the AMI off of. There are several valid keys, for a full reference, check out the
# documentation for describe-images in the AWS CLI reference
# (https://docs.aws.amazon.com/cli/latest/reference/ec2/describe-images.html).
filters = list(object({
name = string
values = list(string)
}))
})
Details
Name/Value pairs to filter the AMI off of. There are several valid keys, for a full reference, check out the
documentation for describe-images in the AWS CLI reference
(https://docs.aws.amazon.com/cli/latest/reference/ec2/describe-images.html).
eks_cluster_namestringThe name of the EKS cluster. The cluster must exist/already be deployed.
Configure one or more Node Groups to manage the EC2 instances in this cluster. Set to empty object ({}) if you do not wish to configure managed node groups.
Any types represent complex values of variable type. For details, please consult `variables.tf` in the source repo.
Details
Each configuration must be keyed by a unique string that will be used as a suffix for the node group name. The
values support the following attributes:
OPTIONAL (defaults to value of corresponding module input):
- subnet_ids list(string) : (Defaults to value from var.node_group_default_subnet_ids) A list of the
subnets into which the EKS Cluster's managed nodes will be launched.
These should usually be all private subnets and include one in each AWS
Availability Zone. NOTE: If using a cluster autoscaler with EBS volumes,
each ASG may only belong to a single availability zone.
- min_size number : (Defaults to value from var.node_group_default_min_size) The minimum
number of EC2 Instances representing workers launchable for this EKS
Cluster. Useful for auto-scaling limits.
- max_size number : (Defaults to value from var.node_group_default_max_size) The maximum
number of EC2 Instances representing workers that must be running for
this EKS Cluster. We recommend making this at least twice the min_size,
even if you don't plan on scaling the cluster up and down, as the extra
capacity will be used to deploy updates to the cluster.
- desired_size number : (Defaults to value from var.node_group_default_desired_size) The current
desired number of EC2 Instances representing workers that must be running
for this EKS Cluster.
- instance_types list(string) : (Defaults to value from var.node_group_default_instance_types) A list of
instance types (e.g., t2.medium) to use for the EKS Cluster's worker
nodes. EKS will choose from this list of instance types when launching
new instances. When using launch templates, this setting will override
the configured instance type of the launch template.
- capacity_type string : (Defaults to value from var.node_group_default_capacity_type) Type of capacity
associated with the EKS Node Group. Valid values: ON_DEMAND, SPOT.
- launch_template LaunchTemplate : (Defaults to value from var.node_group_default_launch_template)
Launch template to use for the node. Specify either Name or ID of launch
template. Must include version. Although the API supports using the
values "$Latest" and "$Default" to configure the version, this can lead
to a perpetual diff. Use the `latest_version` or `default_version` output
of the aws_launch_template data source or resource instead. See
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/eks_node_grouplaunch_template-configuration-block
for more information.
- max_pods_allowed number : (Defaults to value from var.node_group_default_max_pods_allowed) The
maximum number of Pods allowed to be scheduled on the node. When null,
the max will be automatically calculated based on the availability of
total IP addresses to the instance type.
- imds_http_put_response_hop_limit number : (Defaults to value from
var.node_group_default_imds_http_put_response_hop_limit) The desired
HTTP PUT response hop limit for instance metadata requests from the
underlying EC2 Instances.
- instance_root_volume_name string : (Defaults to value from var.node_group_default_instance_root_volume_name)
The root volume name of instances to use for the ASG (e.g., /dev/xvda)
- instance_root_volume_size number : (Defaults to value from var.node_group_default_instance_root_volume_size)
The root volume size of instances to use for the ASG in GB (e.g., 40).
- instance_root_volume_type string : (Defaults to value from var.node_group_default_instance_root_volume_type)
The root volume type of instances to use for the ASG (e.g., "standard").
- instance_root_volume_encryption bool : (Defaults to value from var.node_group_default_instance_root_volume_encryption)
Whether or not to enable root volume encryption for instances of the ASG.
- tags map(string) : (Defaults to value from var.node_group_default_tags) Custom tags to apply
to the EC2 Instances in this node group. This should be a key value pair,
where the keys are tag keys and values are the tag values. Merged with
var.common_tags.
- labels map(string) : (Defaults to value from var.node_group_default_labels) Custom Kubernetes
Labels to apply to the EC2 Instances in this node group. This should be a
key value pair, where the keys are label keys and values are the label
values. Merged with var.common_labels.
- taints list(map(string)) : (Defaults to value from var.node_group_default_taints) Custom Kubernetes
taint to apply to the EC2 Instances in this node group. See below for
structure of taints.
- enable_detailed_monitoring bool : (Defaults to value from
var.node_group_default_enable_detailed_monitoring) Whether to enable
detailed monitoring on the EC2 instances that comprise the Managed node
group.
- eks_kubelet_extra_args string : Extra args to pass to the kubelet process on node boot.
- eks_bootstrap_script_options string : Extra option args to pass to the bootstrap.sh script. This will be
passed through directly to the bootstrap script.
- cloud_init_parts map(string) : (Defaults to value from var.cloud_init_parts)
Per-ASG cloud init scripts to run at boot time on the node. See var.cloud_init_parts for accepted keys.
Structure of LaunchTemplate object:
- name string : The Name of the Launch Template to use. One of ID or Name should be provided.
- id string : The ID of the Launch Template to use. One of ID or Name should be provided.
- version string : The version of the Launch Template to use.
Example:
managed_node_group_configurations = {
ngroup1 = {
desired_size = 1
min_size = 1
max_size = 3
subnet_ids = [data.terraform_remote_state.vpc.outputs.private_app_subnet_ids[0]]
}
asg2 = {
desired_size = 1
min_size = 1
max_size = 3
subnet_ids = [data.terraform_remote_state.vpc.outputs.private_app_subnet_ids[0]]
disk_size = 50
}
ngroup2 = {} Only defaults
}
Optional
additional_security_groups_for_workerslist(string)A list of additional security group IDs to be attached on worker groups.
[]alarms_sns_topic_arnlist(string)The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and disk space usage) should send notifications.
[]allow_inbound_ssh_from_cidr_blockslist(string)The list of CIDR blocks to allow inbound SSH access to the worker groups.
[]allow_inbound_ssh_from_security_groupslist(string)The list of security group IDs to allow inbound SSH access to the worker groups.
[]ami_sourcestringWhere to get the AMI from. Can be 'auto', 'launch_template', or 'eks_nodegroup'. WARNING there are limitation on what the value is, check the documentation for more information https://docs.aws.amazon.com/eks/latest/userguide/launch-templates.html#mng-ami-id-conditions
"auto"asg_custom_iam_role_namestringCustom name for the IAM role for the Self-managed workers. When null, a default name based on worker_name_prefix will be used. One of asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null) if asg_iam_role_already_exists is true.
nullDefault value for enable_detailed_monitoring field of autoscaling_group_configurations.
trueDefault value for the http_put_response_hop_limit field of autoscaling_group_configurations.
nullDefault value for the instance_maintenance_policy field of autoscaling_group_configurations.
object({
min_healthy_percentage = number
max_healthy_percentage = number
})
nullDefault value for the asg_instance_root_volume_encryption field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_root_volume_encryption will use this value.
trueDefault value for the asg_instance_root_volume_iops field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_root_volume_iops will use this value.
nullDefault value for the asg_instance_root_volume_size field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_root_volume_size will use this value.
40Default value for the asg_instance_root_volume_throughput field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_root_volume_throughput will use this value.
nullDefault value for the asg_instance_root_volume_type field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_root_volume_type will use this value.
"standard"Default value for the asg_instance_type field of autoscaling_group_configurations. Any map entry that does not specify asg_instance_type will use this value.
"t3.medium"Default value for the max_pods_allowed field of autoscaling_group_configurations. Any map entry that does not specify max_pods_allowed will use this value.
nullasg_default_max_sizenumberDefault value for the max_size field of autoscaling_group_configurations. Any map entry that does not specify max_size will use this value.
2asg_default_min_sizenumberDefault value for the min_size field of autoscaling_group_configurations. Any map entry that does not specify min_size will use this value.
1Default value for the multi_instance_overrides field of autoscaling_group_configurations. Any map entry that does not specify multi_instance_overrides will use this value.
Any types represent complex values of variable type. For details, please consult `variables.tf` in the source repo.
[]Example
[
{
instance_type = "t3.micro"
weighted_capacity = 2
},
{
instance_type = "t3.medium"
weighted_capacity = 1
},
]
Details
Ideally, we would use a concrete type here, but terraform doesn't support optional attributes yet, so we have to
resort to the untyped any.
Default value for the on_demand_allocation_strategy field of autoscaling_group_configurations. Any map entry that does not specify on_demand_allocation_strategy will use this value.
nullDefault value for the on_demand_base_capacity field of autoscaling_group_configurations. Any map entry that does not specify on_demand_base_capacity will use this value.
nullDefault value for the on_demand_percentage_above_base_capacity field of autoscaling_group_configurations. Any map entry that does not specify on_demand_percentage_above_base_capacity will use this value.
nullDefault value for the spot_allocation_strategy field of autoscaling_group_configurations. Any map entry that does not specify spot_allocation_strategy will use this value.
nullDefault value for the spot_instance_pools field of autoscaling_group_configurations. Any map entry that does not specify spot_instance_pools will use this value.
nullDefault value for the spot_max_price field of autoscaling_group_configurations. Any map entry that does not specify spot_max_price will use this value. Set to empty string (default) to mean on-demand price.
nullasg_default_tagslist(object(…))Default value for the tags field of autoscaling_group_configurations. Any map entry that does not specify tags will use this value.
list(object({
key = string
value = string
propagate_at_launch = bool
}))
[]Default value for the use_multi_instances_policy field of autoscaling_group_configurations. Any map entry that does not specify use_multi_instances_policy will use this value.
falseCustom name for the IAM instance profile for the Self-managed workers. When null, the IAM role name will be used. If asg_use_resource_name_prefix is true, this will be used as a name prefix.
nullWhether or not the IAM role used for the Self-managed workers already exists. When false, this module will create a new IAM role.
falseasg_iam_role_arnstringARN of the IAM role to use if iam_role_already_exists = true. When null, uses asg_custom_iam_role_name to lookup the ARN. One of asg_custom_iam_role_name and asg_iam_role_arn is required (must be non-null) if asg_iam_role_already_exists is true.
nullasg_security_group_tagsmap(string)A map of tags to apply to the Security Group of the ASG for the self managed worker pool. The key is the tag name and the value is the tag value.
{}When true, all the relevant resources for self managed workers will be set to use the name_prefix attribute so that unique names are generated for them. This allows those resources to support recreation through create_before_destroy lifecycle rules. Set to false if you were using any version before 0.65.0 and wish to avoid recreating the entire worker pool on your cluster.
trueBoolean value to enable/disable cloudwatch alarms for the EKS Worker ASG. Defaults to 'true'.
trueasg_worker_iam_policy_tagsmap(string)A map of custom tags to apply to the EKS Worker IAM Policies. The key is the tag name and the value is the tag value.
{}asg_worker_iam_role_tagsmap(string)A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag name and the value is the tag value.
{}asg_worker_instance_profile_tagsmap(string)A map of custom tags to apply to the EKS Worker IAM Instance Profile. The key is the tag name and the value is the tag value.
{}Adds additional tags to each ASG that allow a cluster autoscaler to auto-discover them. Only used for self-managed workers.
trueNamespace where the AWS Auth Merger is deployed. If configured, the worker IAM role will be mapped to the Kubernetes RBAC group for Nodes using a ConfigMap in the auth merger namespace.
nullcloud_init_partsmap(object(…))Cloud init scripts to run on the EKS worker nodes when it is booting. See the part blocks in https://www.terraform.io/docs/providers/template/d/cloudinit_config.html for syntax. To override the default boot script installed as part of the module, use the key default.
map(object({
# A filename to report in the header for the part. Should be unique across all cloud-init parts.
filename = string
# A MIME-style content type to report in the header for the part. For example, use "text/x-shellscript" for a shell
# script.
content_type = string
# The contents of the boot script to be called. This should be the full text of the script as a raw string.
content = string
}))
{}Details
A MIME-style content type to report in the header for the part. For example, use "text/x-shellscript" for a shell
script.
Details
The contents of the boot script to be called. This should be the full text of the script as a raw string.
The ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for encrypting log data. Only used if enable_cloudwatch_log_aggregation is true.
nullName of the CloudWatch Log Group where server system logs are reported to. Only used if enable_cloudwatch_log_aggregation is true.
nullThe number of days to retain log events in the log group. Refer to https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days for all the valid values. When null, the log events are retained forever. Only used if enable_cloudwatch_log_aggregation is true.
nullcloudwatch_log_group_tagsmap(string)Tags to apply on the CloudWatch Log Group, encoded as a map where the keys are tag keys and values are tag values. Only used if enable_cloudwatch_log_aggregation is true.
nullWhether or not to associate a public IP address to the instances of the self managed ASGs. Will only work if the instances are launched in a public subnet.
falseThe name of the Key Pair that can be used to SSH to each instance in the EKS cluster.
nullcustom_egress_security_group_rulesmap(object(…))A map of unique identifiers to egress security group rules to attach to the worker groups.
map(object({
# The network ports and protocol (tcp, udp, all) for which the security group rule applies to.
from_port = number
to_port = number
protocol = string
# The target of the traffic. Only one of the following can be defined; the others must be configured to null.
target_security_group_id = string # The ID of the security group to which the traffic goes to.
cidr_blocks = list(string) # The list of IP CIDR blocks to which the traffic goes to.
}))
{}Details
The target of the traffic. Only one of the following can be defined; the others must be configured to null.
custom_ingress_security_group_rulesmap(object(…))A map of unique identifiers to ingress security group rules to attach to the worker groups.
map(object({
# The network ports and protocol (tcp, udp, all) for which the security group rule applies to.
from_port = number
to_port = number
protocol = string
# The source of the traffic. Only one of the following can be defined; the others must be configured to null.
source_security_group_id = string # The ID of the security group from which the traffic originates from.
cidr_blocks = list(string) # The list of IP CIDR blocks from which the traffic originates from.
}))
{}Details
The source of the traffic. Only one of the following can be defined; the others must be configured to null.
Parameters for the worker cpu usage widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the worker disk usage widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the worker memory usage widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
default_tagsmap(string)A map of default tags to apply to all supported resources in this module. These tags will be merged with any other resource specific tags. The key is the tag name and the value is the tag value.
{}Set to true to enable several basic CloudWatch alarms around CPU usage, memory usage, and disk space usage. If set to true, make sure to specify SNS topics to send notifications to using alarms_sns_topic_arn.
trueSet to true to send logs to CloudWatch. This is useful in combination with https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/logs/cloudwatch-log-aggregation-scripts to do log aggregation in CloudWatch. Note that this is only recommended for aggregating system level logs from the server instances. Container logs should be managed through fluent-bit deployed with eks-core-services.
falseSet to true to add IAM permissions to send custom metrics to CloudWatch. This is useful in combination with https://github.com/gruntwork-io/terraform-aws-monitoring/tree/master/modules/agents/cloudwatch-agent to get memory and disk metrics in CloudWatch for your Bastion host.
trueenable_fail2banboolEnable fail2ban to block brute force log in attempts. Defaults to true.
trueIf you are using ssh-grunt and your IAM users / groups are defined in a separate AWS account, you can use this variable to specify the ARN of an IAM role that ssh-grunt can assume to retrieve IAM group and public SSH key info from that account. To omit this variable, set it to an empty string (do NOT use null, or Terraform will complain).
""The period, in seconds, over which to measure the CPU utilization percentage for the ASG.
60Trigger an alarm if the ASG has an average cluster CPU utilization percentage above this threshold.
90Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"The period, in seconds, over which to measure the root disk utilization percentage for the ASG.
60Trigger an alarm if the ASG has an average cluster root disk utilization percentage above this threshold.
90Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"The period, in seconds, over which to measure the Memory utilization percentage for the ASG.
60Trigger an alarm if the ASG has an average cluster Memory utilization percentage above this threshold.
90Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"Custom name for the IAM role for the Managed Node Groups. When null, a default name based on worker_name_prefix will be used. One of managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn is required (must be non-null) if managed_node_group_iam_role_already_exists is true.
nullWhether or not the IAM role used for the Managed Node Group workers already exists. When false, this module will create a new IAM role.
falseARN of the IAM role to use if iam_role_already_exists = true. When null, uses managed_node_group_custom_iam_role_name to lookup the ARN. One of managed_node_group_custom_iam_role_name and managed_node_group_iam_role_arn is required (must be non-null) if managed_node_group_iam_role_already_exists is true.
nullDefault value for capacity_type field of managed_node_group_configurations.
"ON_DEMAND"Default value for desired_size field of managed_node_group_configurations.
1Default value for enable_detailed_monitoring field of managed_node_group_configurations.
trueDefault value for http_put_response_hop_limit field of managed_node_group_configurations. Any map entry that does not specify http_put_response_hop_limit will use this value.
nullDefault value for the instance_root_volume_encryption field of managed_node_group_configurations.
trueDefault voume name for the instance_root_volume_name field in managed_node_group_configurations.
"/dev/xvda"Default value for the instance_root_volume_size field of managed_node_group_configurations.
40Default value for the instance_root_volume_type field of managed_node_group_configurations.
"gp3"node_group_default_instance_typeslist(string)Default value for instance_types field of managed_node_group_configurations.
nullnode_group_default_labelsmap(string)Default value for labels field of managed_node_group_configurations. Unlike common_labels which will always be merged in, these labels are only used if the labels field is omitted from the configuration.
{}Default value for the max_pods_allowed field of managed_node_group_configurations. Any map entry that does not specify max_pods_allowed will use this value.
nullDefault value for max_size field of managed_node_group_configurations.
1Default value for min_size field of managed_node_group_configurations.
1node_group_default_subnet_idslist(string)Default value for subnet_ids field of managed_node_group_configurations.
nullnode_group_default_tagsmap(string)Default value for tags field of managed_node_group_configurations. Unlike common_tags which will always be merged in, these tags are only used if the tags field is omitted from the configuration.
{}node_group_default_taintslist(map(…))Default value for taint field of node_group_configurations. These taints are only used if the taint field is omitted from the configuration.
list(map(string))
[]The instance type to configure in the launch template. This value will be used when the instance_types field is set to null (NOT omitted, in which case node_group_default_instance_types will be used).
nullTags assigned to a node group are mirrored to the underlaying autoscaling group by default. If you want to disable this behaviour, set this flag to false. Note that this assumes that there is a one-to-one mappping between ASGs and Node Groups. If there is more than one ASG mapped to the Node Group, then this will only apply the tags on the first one. Due to a limitation in Terraform for_each where it can not depend on dynamic data, it is currently not possible in the module to map the tags to all ASGs. If you wish to apply the tags to all underlying ASGs, then it is recommended to call the aws_autoscaling_group_tag resource in a separate terraform state file outside of this module, or use a two-stage apply process.
truenode_group_nameslist(string)The names of the node groups. When null, this value is automatically calculated from the managed_node_group_configurations map. This variable must be set if any of the values of the managed_node_group_configurations map depends on a resource that is not available at plan time to work around terraform limitations with for_each.
nullnode_group_security_group_tagsmap(string)A map of tags to apply to the Security Group of the ASG for the managed node group pool. The key is the tag name and the value is the tag value.
{}node_group_worker_iam_role_tagsmap(string)A map of custom tags to apply to the EKS Worker IAM Role. The key is the tag name and the value is the tag value.
{}ssh_grunt_iam_groupstringIf you are using ssh-grunt, this is the name of the IAM group from which users will be allowed to SSH to the EKS workers. To omit this variable, set it to an empty string (do NOT use null, or Terraform will complain).
"ssh-grunt-users"ssh_grunt_iam_group_sudostringIf you are using ssh-grunt, this is the name of the IAM group from which users will be allowed to SSH to the EKS workers with sudo permissions. To omit this variable, set it to an empty string (do NOT use null, or Terraform will complain).
"ssh-grunt-sudo-users"tenancystringThe tenancy of the servers in the self-managed worker ASG. Must be one of: default, dedicated, or host.
"default"If this variable is set to true, then use an exec-based plugin to authenticate and fetch tokens for EKS. This is useful because EKS clusters use short-lived authentication tokens that can expire in the middle of an 'apply' or 'destroy', and since the native Kubernetes provider in Terraform doesn't have a way to fetch up-to-date tokens, we recommend using an exec-based provider as a workaround. Use the use_kubergrunt_to_fetch_token input variable to control whether kubergrunt or aws is used to fetch tokens.
trueuse_imdsv1boolSet this variable to true to enable the use of Instance Metadata Service Version 1 in this module's aws_launch_template. Note that while IMDsv2 is preferred due to its special security hardening, we allow this in order to support the use case of AMIs built outside of these modules that depend on IMDSv1.
falseEKS clusters use short-lived authentication tokens that can expire in the middle of an 'apply' or 'destroy'. To avoid this issue, we use an exec-based plugin to fetch an up-to-date token. If this variable is set to true, we'll use kubergrunt to fetch the token (in which case, kubergrunt must be installed and on PATH); if this variable is set to false, we'll use the aws CLI to fetch the token (in which case, aws must be installed and on PATH). Note this functionality is only enabled if use_exec_plugin_for_auth is set to true.
trueWhen true, all IAM policies will be managed as dedicated policies rather than inline policies attached to the IAM roles. Dedicated managed policies are friendlier to automated policy checkers, which may scan a single resource for findings. As such, it is important to avoid inline policies when targeting compliance with various security standards.
trueWhen true, assumes prefix delegation mode is in use for the AWS VPC CNI component of the EKS cluster when computing max pods allowed on the node. In prefix delegation mode, each ENI will be allocated 16 IP addresses (/28) instead of 1, allowing you to pack more Pods per node.
falseName of the IAM role to Kubernetes RBAC group mapping ConfigMap. Only used if aws_auth_merger_namespace is not null.
"eks-cluster-worker-iam-mapping"worker_name_prefixstringPrefix EKS worker resource names with this string. When you have multiple worker groups for the cluster, you can use this to namespace the resources. Defaults to empty string so that resource names are not excessively long by default.
""Map of Node Group names to ARNs of the created EKS Node Groups.
The ARN of the IAM role associated with the Managed Node Group EKS workers.
The name of the IAM role associated with the Managed Node Group EKS workers.
Map of Node Group names to Auto Scaling Group security group IDs. Empty if cluster_instance_keypair_name is not set.
The ID of the common AWS Security Group associated with all the managed EKS workers.
A CloudWatch Dashboard widget that graphs CPU usage (percentage) of the Managed Node Group EKS workers.
A CloudWatch Dashboard widget that graphs disk usage (percentage) of the Managed Node Group EKS workers.
A CloudWatch Dashboard widget that graphs memory usage (percentage) of the Managed Node Group EKS workers.
A CloudWatch Dashboard widget that graphs CPU usage (percentage) of the self-managed EKS workers.
A CloudWatch Dashboard widget that graphs disk usage (percentage) of the self-managed EKS workers.
A CloudWatch Dashboard widget that graphs memory usage (percentage) of the self-managed EKS workers.
The ARN of the IAM role associated with the self-managed EKS workers.
The name of the IAM role associated with the self-managed EKS workers.
The ID of the AWS Security Group associated with the self-managed EKS workers.
The list of names of the ASGs that were deployed to act as EKS workers.