Lambda
Overview
This service contains code to deploy a Lambda on AWS that can be used for either production or non-production workloads.
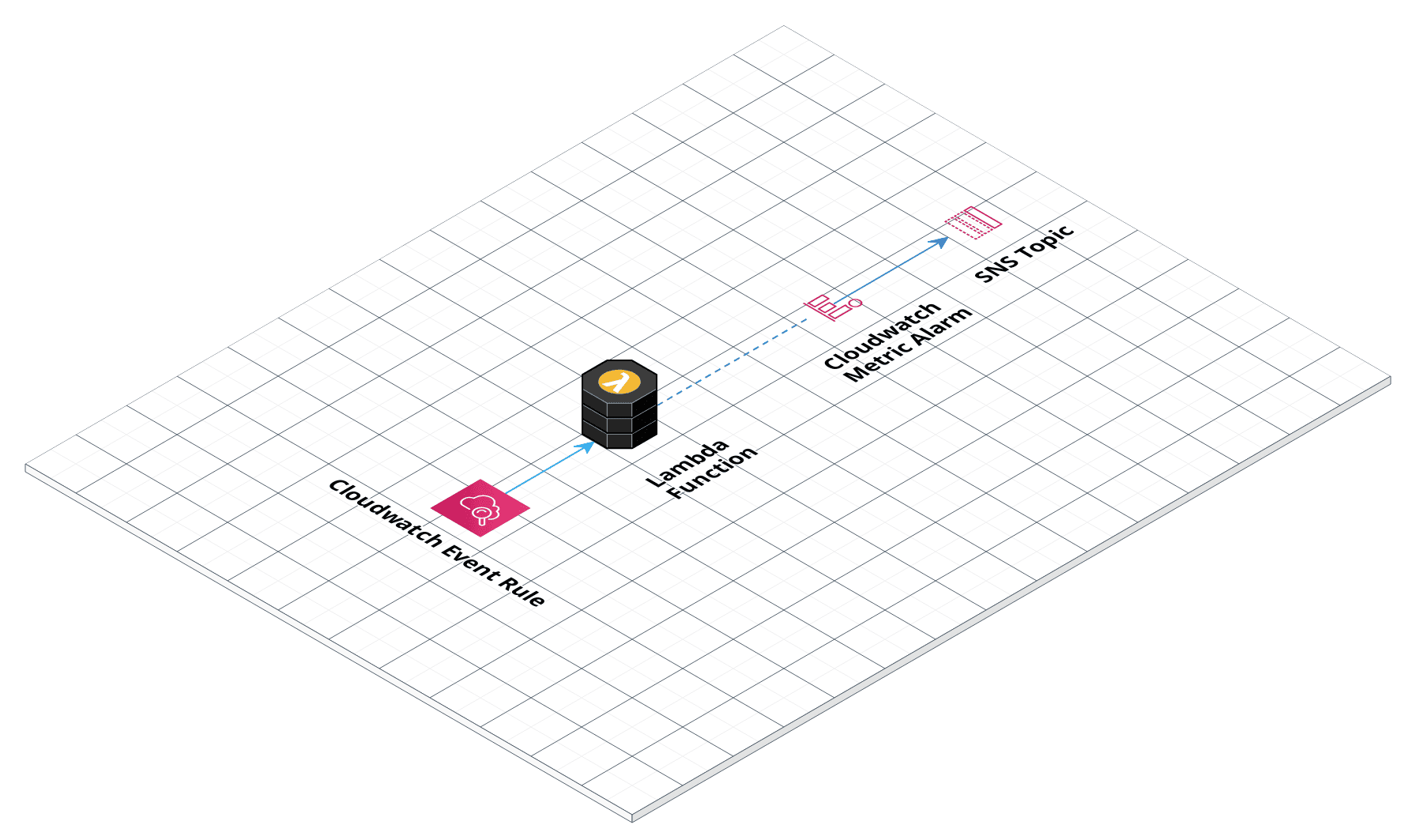 Lambda architecture
Lambda architecture
Features
- The lambda function
- Optionally, a schedule expression if you want to execute the lambda periodically
- Optionally, an alarm that can be triggered when the lambda fails
Learn
This repo is a part of the Gruntwork Service Catalog, a collection of reusable, battle-tested, production ready infrastructure code. If you’ve never used the Service Catalog before, make sure to read How to use the Gruntwork Service Catalog!
Under the hood, this is all implemented using Terraform modules from the Gruntwork terraform-aws-lambda repo. If you are a subscriber and don’t have access to this repo, email support@gruntwork.io.
Core concepts
To understand core concepts like what’s a Lambda, how to test it, and more, see the documentation in the terraform-aws-lambda repo.
Repo organization
- modules: The main implementation code for this repo, broken down into multiple standalone, orthogonal submodules.
- examples: This folder contains working examples of how to use the submodules.
- test: Automated tests for the modules and examples.
Deploy
Non-production deployment (quick start for learning)
If you just want to try this repo out for experimenting and learning, check out the following resources:
- examples/for-learning-and-testing folder: The
examples/for-learning-and-testingfolder contains standalone sample code optimized for learning, experimenting, and testing (but not direct production usage).
Production deployment
If you want to deploy this repo in production, check out the following resources:
-
examples/for-production folder: The
examples/for-productionfolder contains sample code optimized for direct usage in production. This is code from the Gruntwork Reference Architecture, and it shows you how we build an end-to-end, integrated tech stack on top of the Gruntwork Service Catalog. -
How to configure a production-grade CI/CD workflow for application and infrastructure code: step-by-step guide on how to configure CI / CD for your apps and infrastructure.
Sample Usage
- Terraform
- Terragrunt
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S LAMBDA MODULE
# ------------------------------------------------------------------------------------------------------
module "lambda" {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/services/lambda?ref=v2.11.1"
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of SNS topic ARNs to notify when the lambda alarms change to ALARM,
# OK, or INSUFFICIENT_DATA state
alarm_sns_topic_arns = <list(string)>
# The maximum amount of memory, in MB, your Lambda function will be able to
# use at runtime. Can be set in 64MB increments from 128MB up to 1536MB. Note
# that the amount of CPU power given to a Lambda function is proportional to
# the amount of memory you request, so a Lambda function with 256MB of memory
# has twice as much CPU power as one with 128MB.
memory_size = <number>
# The name of the Lambda function. Used to namespace all resources created by
# this module.
name = <string>
# The maximum amount of time, in seconds, your Lambda function will be allowed
# to run. Must be between 1 and 900 seconds.
timeout = <number>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of Security Group IDs that should be attached to the Lambda function
# when running in a VPC. Only used if var.run_in_vpc is true.
additional_security_group_ids = []
# Instruction set architecture for your Lambda function. Valid values are:
# x86_64; arm64. When null, defaults to x86_64.
architecture = null
# A custom assume role policy for the IAM role for this Lambda function. If
# not set, the default is a policy that allows the Lambda service to assume
# the IAM role, which is what most users will need. However, you can use this
# variable to override the policy for special cases, such as using a Lambda
# function to rotate AWS Secrets Manager secrets.
assume_role_policy = null
# The ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for
# encrypting log data.
cloudwatch_log_group_kms_key_id = null
# The number of days to retain log events in the log group. Refer to
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days
# for all the valid values. When null, the log events are retained forever.
cloudwatch_log_group_retention_in_days = null
# The ARN of the destination to deliver matching log events to. Kinesis stream
# or Lambda function ARN. Only applicable if
# var.should_create_cloudwatch_log_group is true.
cloudwatch_log_group_subscription_destination_arn = null
# The method used to distribute log data to the destination. Only applicable
# when var.cloudwatch_log_group_subscription_destination_arn is a kinesis
# stream. Valid values are `Random` and `ByLogStream`.
cloudwatch_log_group_subscription_distribution = null
# A valid CloudWatch Logs filter pattern for subscribing to a filtered stream
# of log events.
cloudwatch_log_group_subscription_filter_pattern = ""
# ARN of an IAM role that grants Amazon CloudWatch Logs permissions to deliver
# ingested log events to the destination. Only applicable when
# var.cloudwatch_log_group_subscription_destination_arn is a kinesis stream.
cloudwatch_log_group_subscription_role_arn = null
# Tags to apply on the CloudWatch Log Group, encoded as a map where the keys
# are tag keys and values are tag values.
cloudwatch_log_group_tags = null
# The CMD for the docker image. Only used if you specify a Docker image via
# image_uri.
command = []
# The arithmetic operation to use when comparing the specified Statistic and
# Threshold. The specified Statistic value is used as the first operand.
# Either of the following is supported: `GreaterThanOrEqualToThreshold`,
# `GreaterThanThreshold`, `LessThanThreshold`, `LessThanOrEqualToThreshold`.
# Additionally, the values `LessThanLowerOrGreaterThanUpperThreshold`,
# `LessThanLowerThreshold`, and `GreaterThanUpperThreshold` are used only for
# alarms based on anomaly detection models.
comparison_operator = "GreaterThanThreshold"
# Set to false to have this module skip creating resources. This weird
# parameter exists solely because Terraform does not support conditional
# modules. Therefore, this is a hack to allow you to conditionally decide if
# this module should create anything or not.
create_resources = true
# The number of datapoints that must be breaching to trigger the alarm.
datapoints_to_alarm = 1
# The ARN of an SNS topic or an SQS queue to notify when invocation of a
# Lambda function fails. If this option is used, you must grant this
# function's IAM role (the ID is outputted as iam_role_id) access to write to
# the target object, which means allowing either the sns:Publish or
# sqs:SendMessage action on this ARN, depending on which service is targeted.
dead_letter_target_arn = null
# A description of what the Lambda function does.
description = null
# Set to true to enable versioning for this Lambda function. This allows you
# to use aliases to refer to execute different versions of the function in
# different environments. Note that an alternative way to run Lambda functions
# in multiple environments is to version your Terraform code.
enable_versioning = false
# The ENTRYPOINT for the docker image. Only used if you specify a Docker image
# via image_uri.
entry_point = []
# A map of environment variables to pass to the Lambda function. AWS will
# automatically encrypt these with KMS and decrypt them when running the
# function.
environment_variables = {"EnvVarPlaceHolder":"Placeholder"}
# The amount of Ephemeral storage(/tmp) to allocate for the Lambda Function in
# MB. This parameter is used to expand the total amount of Ephemeral storage
# available, beyond the default amount of 512MB.
ephemeral_storage = null
# The number of periods over which data is compared to the specified
# threshold.
evaluation_periods = 1
# The ARN of an EFS access point to use to access the file system. Only used
# if var.mount_to_file_system is true.
file_system_access_point_arn = null
# The mount path where the lambda can access the file system. This path must
# begin with /mnt/. Only used if var.mount_to_file_system is true.
file_system_mount_path = null
# The function entrypoint in your code. This is typically the name of a
# function or method in your code that AWS will execute when this Lambda
# function is triggered.
handler = null
# An object defining the policy to attach to `iam_role_name` if the IAM role
# is going to be created. Accepts a map of objects, where the map keys are
# sids for IAM policy statements, and the object fields are the resources,
# actions, and the effect ("Allow" or "Deny") of the statement. Ignored if
# `iam_role_arn` is provided. Leave as null if you do not wish to use IAM role
# with Service Accounts.
iam_policy = null
# The name to use for the IAM role created for the lambda function. If null,
# default to the function name (var.name).
iam_role_name = null
# The ECR image URI containing the function's deployment package. Example:
# 01234501234501.dkr.ecr.us-east-1.amazonaws.com/image_name:image_tag
image_uri = null
# A custom KMS key to use to encrypt and decrypt Lambda function environment
# variables. Leave it blank to use the default KMS key provided in your AWS
# account.
kms_key_arn = null
# The ARN of the policy that is used to set the permissions boundary for the
# IAM role for the lambda
lambda_role_permissions_boundary_arn = null
# The list of Lambda Layer Version ARNs to attach to your Lambda Function. You
# can have a maximum of 5 Layers attached to each function.
layers = []
# Time to wait after creating managed policy, to avoid AWS eventual
# consistency racing. Default: 60s.
managed_policy_waiting_time = "60s"
# The name for the alarm's associated metric.
metric_name = "Errors"
# Set to true to mount your Lambda function on an EFS. Note that the lambda
# must also be deployed inside a VPC (run_in_vpc must be set to true) for this
# config to have any effect.
mount_to_file_system = false
# The namespace to use for all resources created by this module. If not set,
# var.lambda_function_name, with '-scheduled' as a suffix, is used.
namespace = null
# The period in seconds over which the specified `statistic` is applied.
period = 60
# The amount of reserved concurrent executions for this lambda function or -1
# if unreserved.
reserved_concurrent_executions = null
# Set to true to give your Lambda function access to resources within a VPC.
run_in_vpc = false
# The runtime environment for the Lambda function (e.g. nodejs, python2.7,
# java8). See
# https://docs.aws.amazon.com/lambda/latest/dg/API_CreateFunction.html#SSS-CreateFunction-request-Runtime
# for all possible values.
runtime = null
# An S3 bucket location containing the function's deployment package. Exactly
# one of var.source_path or the var.s3_xxx variables must be specified.
s3_bucket = null
# The path within var.s3_bucket where the deployment package is located.
# Exactly one of var.source_path or the var.s3_xxx variables must be
# specified.
s3_key = null
# The version of the path in var.s3_key to use as the deployment package.
# Exactly one of var.source_path or the var.s3_xxx variables must be
# specified.
s3_object_version = null
# An expression that defines the schedule for this lambda job. For example,
# cron(0 20 * * ? *) or rate(5 minutes). For more information visit
# https://docs.aws.amazon.com/lambda/latest/dg/services-cloudwatchevents-expressions.html
schedule_expression = null
# If set to false, this function will no longer set the source_code_hash
# parameter, so this module will no longer detect and upload changes to the
# deployment package. This is primarily useful if you update the Lambda
# function from outside of this module (e.g., you have scripts that do it
# separately) and want to avoid a plan diff. Used only if var.source_path is
# non-empty.
set_source_code_hash = true
# When true, precreate the CloudWatch Log Group to use for log aggregation
# from the lambda function execution. This is useful if you wish to customize
# the CloudWatch Log Group with various settings such as retention periods and
# KMS encryption. When false, AWS Lambda will automatically create a basic log
# group to use.
should_create_cloudwatch_log_group = true
# If true, create an egress rule allowing all outbound traffic from Lambda
# function to the entire Internet (e.g. 0.0.0.0/0).
should_create_outbound_rule = false
# Set to true to skip zip archive creation and assume that var.source_path
# points to a pregenerated zip archive.
skip_zip = false
# The path to the directory that contains your Lambda function source code.
# This code will be zipped up and uploaded to Lambda as your deployment
# package. If var.skip_zip is set to true, then this is assumed to be the path
# to an already-zipped file, and it will be uploaded directly to Lambda as a
# deployment package. Exactly one of var.source_path or the var.s3_xxx
# variables must be specified.
source_path = null
# The statistic to apply to the alarm's associated metric.
statistic = "Sum"
# A list of subnet IDs the Lambda function should be able to access within
# your VPC. Only used if var.run_in_vpc is true.
subnet_ids = []
# A map of tags to apply to the Lambda function.
tags = {}
# The value against which the specified statistic is compared. This parameter
# is required for alarms based on static thresholds, but should not be used
# for alarms based on anomaly detection models.
threshold = 0
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Must
# be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
treat_missing_data = "missing"
# When true, all IAM policies will be managed as dedicated policies rather
# than inline policies attached to the IAM roles. Dedicated managed policies
# are friendlier to automated policy checkers, which may scan a single
# resource for findings. As such, it is important to avoid inline policies
# when targeting compliance with various security standards.
use_managed_iam_policies = true
# The ID of the VPC the Lambda function should be able to access. Only used if
# var.run_in_vpc is true.
vpc_id = null
# The working directory for the docker image. Only used if you specify a
# Docker image via image_uri.
working_directory = null
# The path to store the output zip file of your source code. If empty,
# defaults to module path. This should be the full path to the zip file, not a
# directory.
zip_output_path = null
}
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S LAMBDA MODULE
# ------------------------------------------------------------------------------------------------------
terraform {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/services/lambda?ref=v2.11.1"
}
inputs = {
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of SNS topic ARNs to notify when the lambda alarms change to ALARM,
# OK, or INSUFFICIENT_DATA state
alarm_sns_topic_arns = <list(string)>
# The maximum amount of memory, in MB, your Lambda function will be able to
# use at runtime. Can be set in 64MB increments from 128MB up to 1536MB. Note
# that the amount of CPU power given to a Lambda function is proportional to
# the amount of memory you request, so a Lambda function with 256MB of memory
# has twice as much CPU power as one with 128MB.
memory_size = <number>
# The name of the Lambda function. Used to namespace all resources created by
# this module.
name = <string>
# The maximum amount of time, in seconds, your Lambda function will be allowed
# to run. Must be between 1 and 900 seconds.
timeout = <number>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# A list of Security Group IDs that should be attached to the Lambda function
# when running in a VPC. Only used if var.run_in_vpc is true.
additional_security_group_ids = []
# Instruction set architecture for your Lambda function. Valid values are:
# x86_64; arm64. When null, defaults to x86_64.
architecture = null
# A custom assume role policy for the IAM role for this Lambda function. If
# not set, the default is a policy that allows the Lambda service to assume
# the IAM role, which is what most users will need. However, you can use this
# variable to override the policy for special cases, such as using a Lambda
# function to rotate AWS Secrets Manager secrets.
assume_role_policy = null
# The ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for
# encrypting log data.
cloudwatch_log_group_kms_key_id = null
# The number of days to retain log events in the log group. Refer to
# https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days
# for all the valid values. When null, the log events are retained forever.
cloudwatch_log_group_retention_in_days = null
# The ARN of the destination to deliver matching log events to. Kinesis stream
# or Lambda function ARN. Only applicable if
# var.should_create_cloudwatch_log_group is true.
cloudwatch_log_group_subscription_destination_arn = null
# The method used to distribute log data to the destination. Only applicable
# when var.cloudwatch_log_group_subscription_destination_arn is a kinesis
# stream. Valid values are `Random` and `ByLogStream`.
cloudwatch_log_group_subscription_distribution = null
# A valid CloudWatch Logs filter pattern for subscribing to a filtered stream
# of log events.
cloudwatch_log_group_subscription_filter_pattern = ""
# ARN of an IAM role that grants Amazon CloudWatch Logs permissions to deliver
# ingested log events to the destination. Only applicable when
# var.cloudwatch_log_group_subscription_destination_arn is a kinesis stream.
cloudwatch_log_group_subscription_role_arn = null
# Tags to apply on the CloudWatch Log Group, encoded as a map where the keys
# are tag keys and values are tag values.
cloudwatch_log_group_tags = null
# The CMD for the docker image. Only used if you specify a Docker image via
# image_uri.
command = []
# The arithmetic operation to use when comparing the specified Statistic and
# Threshold. The specified Statistic value is used as the first operand.
# Either of the following is supported: `GreaterThanOrEqualToThreshold`,
# `GreaterThanThreshold`, `LessThanThreshold`, `LessThanOrEqualToThreshold`.
# Additionally, the values `LessThanLowerOrGreaterThanUpperThreshold`,
# `LessThanLowerThreshold`, and `GreaterThanUpperThreshold` are used only for
# alarms based on anomaly detection models.
comparison_operator = "GreaterThanThreshold"
# Set to false to have this module skip creating resources. This weird
# parameter exists solely because Terraform does not support conditional
# modules. Therefore, this is a hack to allow you to conditionally decide if
# this module should create anything or not.
create_resources = true
# The number of datapoints that must be breaching to trigger the alarm.
datapoints_to_alarm = 1
# The ARN of an SNS topic or an SQS queue to notify when invocation of a
# Lambda function fails. If this option is used, you must grant this
# function's IAM role (the ID is outputted as iam_role_id) access to write to
# the target object, which means allowing either the sns:Publish or
# sqs:SendMessage action on this ARN, depending on which service is targeted.
dead_letter_target_arn = null
# A description of what the Lambda function does.
description = null
# Set to true to enable versioning for this Lambda function. This allows you
# to use aliases to refer to execute different versions of the function in
# different environments. Note that an alternative way to run Lambda functions
# in multiple environments is to version your Terraform code.
enable_versioning = false
# The ENTRYPOINT for the docker image. Only used if you specify a Docker image
# via image_uri.
entry_point = []
# A map of environment variables to pass to the Lambda function. AWS will
# automatically encrypt these with KMS and decrypt them when running the
# function.
environment_variables = {"EnvVarPlaceHolder":"Placeholder"}
# The amount of Ephemeral storage(/tmp) to allocate for the Lambda Function in
# MB. This parameter is used to expand the total amount of Ephemeral storage
# available, beyond the default amount of 512MB.
ephemeral_storage = null
# The number of periods over which data is compared to the specified
# threshold.
evaluation_periods = 1
# The ARN of an EFS access point to use to access the file system. Only used
# if var.mount_to_file_system is true.
file_system_access_point_arn = null
# The mount path where the lambda can access the file system. This path must
# begin with /mnt/. Only used if var.mount_to_file_system is true.
file_system_mount_path = null
# The function entrypoint in your code. This is typically the name of a
# function or method in your code that AWS will execute when this Lambda
# function is triggered.
handler = null
# An object defining the policy to attach to `iam_role_name` if the IAM role
# is going to be created. Accepts a map of objects, where the map keys are
# sids for IAM policy statements, and the object fields are the resources,
# actions, and the effect ("Allow" or "Deny") of the statement. Ignored if
# `iam_role_arn` is provided. Leave as null if you do not wish to use IAM role
# with Service Accounts.
iam_policy = null
# The name to use for the IAM role created for the lambda function. If null,
# default to the function name (var.name).
iam_role_name = null
# The ECR image URI containing the function's deployment package. Example:
# 01234501234501.dkr.ecr.us-east-1.amazonaws.com/image_name:image_tag
image_uri = null
# A custom KMS key to use to encrypt and decrypt Lambda function environment
# variables. Leave it blank to use the default KMS key provided in your AWS
# account.
kms_key_arn = null
# The ARN of the policy that is used to set the permissions boundary for the
# IAM role for the lambda
lambda_role_permissions_boundary_arn = null
# The list of Lambda Layer Version ARNs to attach to your Lambda Function. You
# can have a maximum of 5 Layers attached to each function.
layers = []
# Time to wait after creating managed policy, to avoid AWS eventual
# consistency racing. Default: 60s.
managed_policy_waiting_time = "60s"
# The name for the alarm's associated metric.
metric_name = "Errors"
# Set to true to mount your Lambda function on an EFS. Note that the lambda
# must also be deployed inside a VPC (run_in_vpc must be set to true) for this
# config to have any effect.
mount_to_file_system = false
# The namespace to use for all resources created by this module. If not set,
# var.lambda_function_name, with '-scheduled' as a suffix, is used.
namespace = null
# The period in seconds over which the specified `statistic` is applied.
period = 60
# The amount of reserved concurrent executions for this lambda function or -1
# if unreserved.
reserved_concurrent_executions = null
# Set to true to give your Lambda function access to resources within a VPC.
run_in_vpc = false
# The runtime environment for the Lambda function (e.g. nodejs, python2.7,
# java8). See
# https://docs.aws.amazon.com/lambda/latest/dg/API_CreateFunction.html#SSS-CreateFunction-request-Runtime
# for all possible values.
runtime = null
# An S3 bucket location containing the function's deployment package. Exactly
# one of var.source_path or the var.s3_xxx variables must be specified.
s3_bucket = null
# The path within var.s3_bucket where the deployment package is located.
# Exactly one of var.source_path or the var.s3_xxx variables must be
# specified.
s3_key = null
# The version of the path in var.s3_key to use as the deployment package.
# Exactly one of var.source_path or the var.s3_xxx variables must be
# specified.
s3_object_version = null
# An expression that defines the schedule for this lambda job. For example,
# cron(0 20 * * ? *) or rate(5 minutes). For more information visit
# https://docs.aws.amazon.com/lambda/latest/dg/services-cloudwatchevents-expressions.html
schedule_expression = null
# If set to false, this function will no longer set the source_code_hash
# parameter, so this module will no longer detect and upload changes to the
# deployment package. This is primarily useful if you update the Lambda
# function from outside of this module (e.g., you have scripts that do it
# separately) and want to avoid a plan diff. Used only if var.source_path is
# non-empty.
set_source_code_hash = true
# When true, precreate the CloudWatch Log Group to use for log aggregation
# from the lambda function execution. This is useful if you wish to customize
# the CloudWatch Log Group with various settings such as retention periods and
# KMS encryption. When false, AWS Lambda will automatically create a basic log
# group to use.
should_create_cloudwatch_log_group = true
# If true, create an egress rule allowing all outbound traffic from Lambda
# function to the entire Internet (e.g. 0.0.0.0/0).
should_create_outbound_rule = false
# Set to true to skip zip archive creation and assume that var.source_path
# points to a pregenerated zip archive.
skip_zip = false
# The path to the directory that contains your Lambda function source code.
# This code will be zipped up and uploaded to Lambda as your deployment
# package. If var.skip_zip is set to true, then this is assumed to be the path
# to an already-zipped file, and it will be uploaded directly to Lambda as a
# deployment package. Exactly one of var.source_path or the var.s3_xxx
# variables must be specified.
source_path = null
# The statistic to apply to the alarm's associated metric.
statistic = "Sum"
# A list of subnet IDs the Lambda function should be able to access within
# your VPC. Only used if var.run_in_vpc is true.
subnet_ids = []
# A map of tags to apply to the Lambda function.
tags = {}
# The value against which the specified statistic is compared. This parameter
# is required for alarms based on static thresholds, but should not be used
# for alarms based on anomaly detection models.
threshold = 0
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Must
# be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
treat_missing_data = "missing"
# When true, all IAM policies will be managed as dedicated policies rather
# than inline policies attached to the IAM roles. Dedicated managed policies
# are friendlier to automated policy checkers, which may scan a single
# resource for findings. As such, it is important to avoid inline policies
# when targeting compliance with various security standards.
use_managed_iam_policies = true
# The ID of the VPC the Lambda function should be able to access. Only used if
# var.run_in_vpc is true.
vpc_id = null
# The working directory for the docker image. Only used if you specify a
# Docker image via image_uri.
working_directory = null
# The path to store the output zip file of your source code. If empty,
# defaults to module path. This should be the full path to the zip file, not a
# directory.
zip_output_path = null
}
Reference
- Inputs
- Outputs
Required
alarm_sns_topic_arnslist(string)A list of SNS topic ARNs to notify when the lambda alarms change to ALARM, OK, or INSUFFICIENT_DATA state
memory_sizenumberThe maximum amount of memory, in MB, your Lambda function will be able to use at runtime. Can be set in 64MB increments from 128MB up to 1536MB. Note that the amount of CPU power given to a Lambda function is proportional to the amount of memory you request, so a Lambda function with 256MB of memory has twice as much CPU power as one with 128MB.
namestringThe name of the Lambda function. Used to namespace all resources created by this module.
timeoutnumberThe maximum amount of time, in seconds, your Lambda function will be allowed to run. Must be between 1 and 900 seconds.
Optional
additional_security_group_idslist(string)A list of Security Group IDs that should be attached to the Lambda function when running in a VPC. Only used if run_in_vpc is true.
[]architecturestringInstruction set architecture for your Lambda function. Valid values are: x86_64; arm64. When null, defaults to x86_64.
nullassume_role_policystringA custom assume role policy for the IAM role for this Lambda function. If not set, the default is a policy that allows the Lambda service to assume the IAM role, which is what most users will need. However, you can use this variable to override the policy for special cases, such as using a Lambda function to rotate AWS Secrets Manager secrets.
nullThe ID (ARN, alias ARN, AWS ID) of a customer managed KMS Key to use for encrypting log data.
nullThe number of days to retain log events in the log group. Refer to https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/cloudwatch_log_group#retention_in_days for all the valid values. When null, the log events are retained forever.
nullThe ARN of the destination to deliver matching log events to. Kinesis stream or Lambda function ARN. Only applicable if should_create_cloudwatch_log_group is true.
nullThe method used to distribute log data to the destination. Only applicable when cloudwatch_log_group_subscription_destination_arn is a kinesis stream. Valid values are Random and ByLogStream.
nullA valid CloudWatch Logs filter pattern for subscribing to a filtered stream of log events.
""ARN of an IAM role that grants Amazon CloudWatch Logs permissions to deliver ingested log events to the destination. Only applicable when cloudwatch_log_group_subscription_destination_arn is a kinesis stream.
nullcloudwatch_log_group_tagsmap(string)Tags to apply on the CloudWatch Log Group, encoded as a map where the keys are tag keys and values are tag values.
nullcommandlist(string)The CMD for the docker image. Only used if you specify a Docker image via image_uri.
[]comparison_operatorstringThe arithmetic operation to use when comparing the specified Statistic and Threshold. The specified Statistic value is used as the first operand. Either of the following is supported: GreaterThanOrEqualToThreshold, GreaterThanThreshold, LessThanThreshold, LessThanOrEqualToThreshold. Additionally, the values LessThanLowerOrGreaterThanUpperThreshold, LessThanLowerThreshold, and GreaterThanUpperThreshold are used only for alarms based on anomaly detection models.
"GreaterThanThreshold"create_resourcesboolSet to false to have this module skip creating resources. This weird parameter exists solely because Terraform does not support conditional modules. Therefore, this is a hack to allow you to conditionally decide if this module should create anything or not.
truedatapoints_to_alarmnumberThe number of datapoints that must be breaching to trigger the alarm.
1The ARN of an SNS topic or an SQS queue to notify when invocation of a Lambda function fails. If this option is used, you must grant this function's IAM role (the ID is outputted as iam_role_id) access to write to the target object, which means allowing either the sns:Publish or sqs:SendMessage action on this ARN, depending on which service is targeted.
nulldescriptionstringA description of what the Lambda function does.
nullSet to true to enable versioning for this Lambda function. This allows you to use aliases to refer to execute different versions of the function in different environments. Note that an alternative way to run Lambda functions in multiple environments is to version your Terraform code.
falseentry_pointlist(string)The ENTRYPOINT for the docker image. Only used if you specify a Docker image via image_uri.
[]environment_variablesmap(string)A map of environment variables to pass to the Lambda function. AWS will automatically encrypt these with KMS and decrypt them when running the function.
{
EnvVarPlaceHolder = "Placeholder"
}
Details
Lambda does not permit you to pass it an empty map of environment variables, so our default value has to contain
this totally useless placeholder.
ephemeral_storagenumberThe amount of Ephemeral storage(/tmp) to allocate for the Lambda Function in MB. This parameter is used to expand the total amount of Ephemeral storage available, beyond the default amount of 512MB.
nullevaluation_periodsnumberThe number of periods over which data is compared to the specified threshold.
1The ARN of an EFS access point to use to access the file system. Only used if mount_to_file_system is true.
nullfile_system_mount_pathstringThe mount path where the lambda can access the file system. This path must begin with /mnt/. Only used if mount_to_file_system is true.
nullhandlerstringThe function entrypoint in your code. This is typically the name of a function or method in your code that AWS will execute when this Lambda function is triggered.
nulliam_policymap(object(…))An object defining the policy to attach to iam_role_name if the IAM role is going to be created. Accepts a map of objects, where the map keys are sids for IAM policy statements, and the object fields are the resources, actions, and the effect ('Allow' or 'Deny') of the statement. Ignored if iam_role_arn is provided. Leave as null if you do not wish to use IAM role with Service Accounts.
map(object({
resources = list(string)
actions = list(string)
effect = string
}))
nullExample
iam_policy = {
S3Access = {
actions = ["s3:*"]
resources = ["arn:aws:s3:::mybucket"]
effect = "Allow"
},
SecretsManagerAccess = {
actions = ["secretsmanager:GetSecretValue"],
resources = ["arn:aws:secretsmanager:us-east-1:0123456789012:secret:mysecert"]
effect = "Allow"
}
}
iam_role_namestringThe name to use for the IAM role created for the lambda function. If null, default to the function name (name).
nullimage_uristringThe ECR image URI containing the function's deployment package. Example: 01234501234501.dkr.ecr.us-east-1.amazonaws.com/image_name:image_tag
nullkms_key_arnstringA custom KMS key to use to encrypt and decrypt Lambda function environment variables. Leave it blank to use the default KMS key provided in your AWS account.
nullThe ARN of the policy that is used to set the permissions boundary for the IAM role for the lambda
nulllayerslist(string)The list of Lambda Layer Version ARNs to attach to your Lambda Function. You can have a maximum of 5 Layers attached to each function.
[]Time to wait after creating managed policy, to avoid AWS eventual consistency racing. Default: 60s.
"60s"metric_namestringThe name for the alarm's associated metric.
"Errors"Set to true to mount your Lambda function on an EFS. Note that the lambda must also be deployed inside a VPC (run_in_vpc must be set to true) for this config to have any effect.
falsenamespacestringThe namespace to use for all resources created by this module. If not set, lambda_function_name, with '-scheduled' as a suffix, is used.
nullperiodnumberThe period in seconds over which the specified statistic is applied.
60The amount of reserved concurrent executions for this lambda function or -1 if unreserved.
nullrun_in_vpcboolSet to true to give your Lambda function access to resources within a VPC.
falseruntimestringThe runtime environment for the Lambda function (e.g. nodejs, python2.7, java8). See https://docs.aws.amazon.com/lambda/latest/dg/API_CreateFunction.html#SSS-CreateFunction-request-Runtime for all possible values.
nulls3_bucketstringAn S3 bucket location containing the function's deployment package. Exactly one of source_path or the s3_xxx variables must be specified.
nulls3_keystringThe path within s3_bucket where the deployment package is located. Exactly one of source_path or the s3_xxx variables must be specified.
nulls3_object_versionstringThe version of the path in s3_key to use as the deployment package. Exactly one of source_path or the s3_xxx variables must be specified.
nullschedule_expressionstringAn expression that defines the schedule for this lambda job. For example, cron(0 20 * * ? *) or rate(5 minutes). For more information visit https://docs.aws.amazon.com/lambda/latest/dg/services-cloudwatchevents-expressions.html
nullIf set to false, this function will no longer set the source_code_hash parameter, so this module will no longer detect and upload changes to the deployment package. This is primarily useful if you update the Lambda function from outside of this module (e.g., you have scripts that do it separately) and want to avoid a plan diff. Used only if source_path is non-empty.
trueWhen true, precreate the CloudWatch Log Group to use for log aggregation from the lambda function execution. This is useful if you wish to customize the CloudWatch Log Group with various settings such as retention periods and KMS encryption. When false, AWS Lambda will automatically create a basic log group to use.
trueIf true, create an egress rule allowing all outbound traffic from Lambda function to the entire Internet (e.g. 0.0.0.0/0).
falseskip_zipboolSet to true to skip zip archive creation and assume that source_path points to a pregenerated zip archive.
falsesource_pathstringThe path to the directory that contains your Lambda function source code. This code will be zipped up and uploaded to Lambda as your deployment package. If skip_zip is set to true, then this is assumed to be the path to an already-zipped file, and it will be uploaded directly to Lambda as a deployment package. Exactly one of source_path or the s3_xxx variables must be specified.
nullstatisticstringThe statistic to apply to the alarm's associated metric.
"Sum"subnet_idslist(string)A list of subnet IDs the Lambda function should be able to access within your VPC. Only used if run_in_vpc is true.
[]tagsmap(string)A map of tags to apply to the Lambda function.
{}thresholdnumberThe value against which the specified statistic is compared. This parameter is required for alarms based on static thresholds, but should not be used for alarms based on anomaly detection models.
0treat_missing_datastringSets how this alarm should handle entering the INSUFFICIENT_DATA state. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"When true, all IAM policies will be managed as dedicated policies rather than inline policies attached to the IAM roles. Dedicated managed policies are friendlier to automated policy checkers, which may scan a single resource for findings. As such, it is important to avoid inline policies when targeting compliance with various security standards.
truevpc_idstringThe ID of the VPC the Lambda function should be able to access. Only used if run_in_vpc is true.
nullworking_directorystringThe working directory for the docker image. Only used if you specify a Docker image via image_uri.
nullzip_output_pathstringThe path to store the output zip file of your source code. If empty, defaults to module path. This should be the full path to the zip file, not a directory.
nullThe list of actions to execute when this alarm transitions into an ALARM state from any other state
ARN of the Cloudwatch alarm
Name of the Cloudwatch alarm
Name of the (optionally) created CloudWatch log group for the lambda function.
Cloudwatch Event Rule Arn
Cloudwatch Event Rule schedule expression
Amazon Resource Name (ARN) identifying the Lambda Function
Unique name for Lambda Function
Amazon Resource Name (ARN) of the AWS IAM Role created for the Lambda Function
Name of the AWS IAM Role created for the Lambda Function
The list of actions to execute when this alarm transitions into an INSUFFICIENT_DATA state from any other state
Amazon Resource Name (ARN) to be used for invoking the Lambda Function
The list of actions to execute when this alarm transitions into an OK state from any other state
Amazon Resource Name (ARN) identifying your Lambda Function version
Security Group ID of the Security Group created for the Lambda Function
Latest published version of your Lambda Function