Amazon Aurora
Overview
This service contains code to deploy an Amazon Relational Database Service (RDS) cluster that can run Amazon Aurora, Amazon’s cloud-native relational database. The cluster is managed by AWS and automatically handles standby failover, read replicas, backups, patching, and encryption.
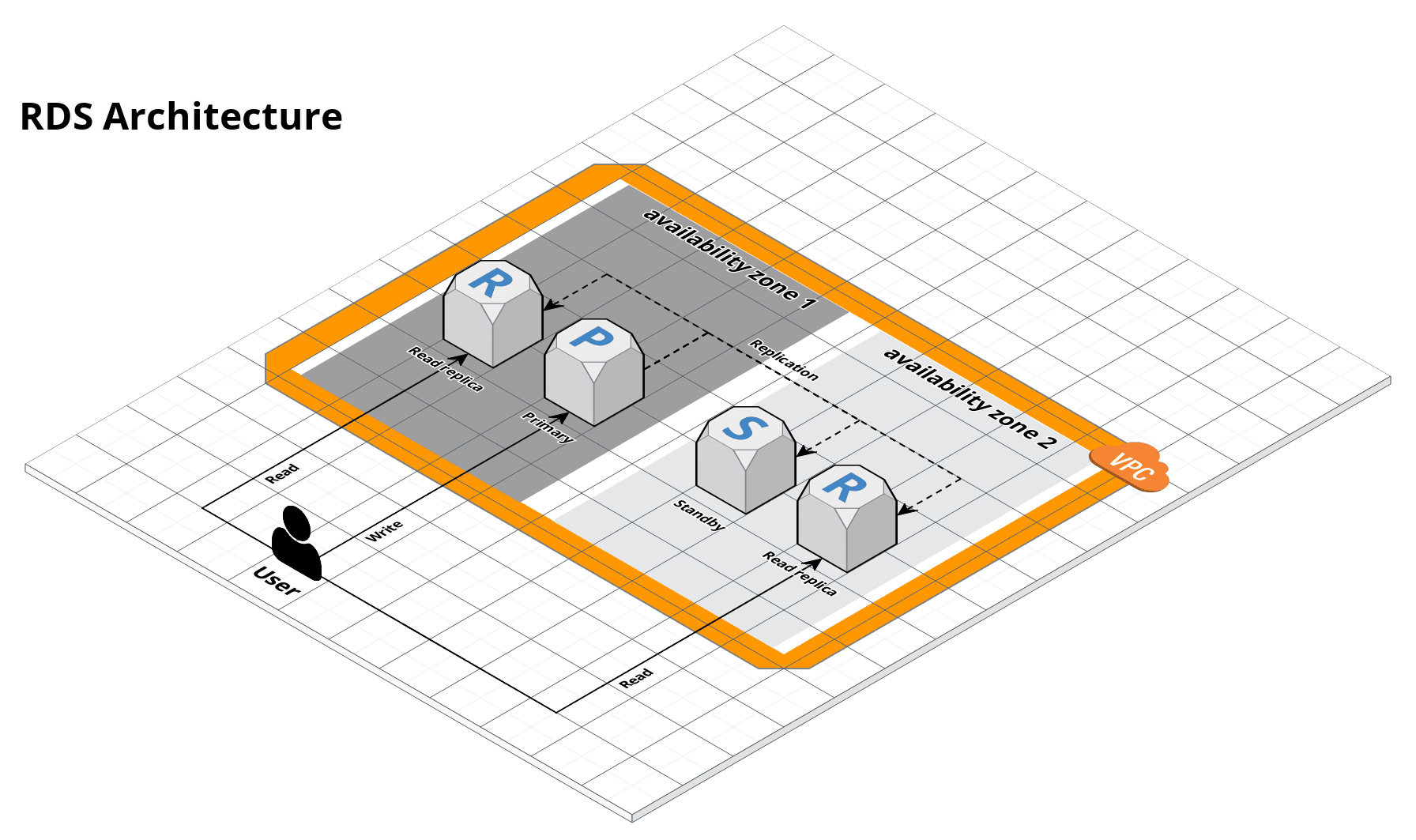 RDS architecture
RDS architecture
Features
- Deploy a fully-managed, cloud-native relational database
- MySQL and PostgreSQL compatibility
- Automatic failover to a standby in another availability zone
- Read replicas
- Automatic nightly snapshots
- Automatic cross account snapshots
- Automatic scaling of storage
- Scale to 0 with Aurora Serverless
- Integrate with Kubernetes Service Discovery
- Support Aurora Serverless v2
Learn
This repo is a part of the Gruntwork Service Catalog, a collection of reusable, battle-tested, production ready infrastructure code. If you’ve never used the Service Catalog before, make sure to read How to use the Gruntwork Service Catalog!
- What is Amazon RDS?
- Common gotchas with RDS
- Aurora Serverless documentation: Amazon’s docs for Aurora Serverless, including its advantages, limitations, architecture, and scaling configurations.
- RDS documentation: Amazon’s docs for RDS that cover core concepts such a the types of databases supported, security, backup & restore, and monitoring.
- Designing Data Intensive Applications: the best book we’ve found for understanding data systems, including relational databases, NoSQL, replication, sharding, consistency, and so on.
Deploy
Non-production deployment (quick start for learning)
If you just want to try this repo out for experimenting and learning, check out the following resources:
- examples/for-learning-and-testing folder: The
examples/for-learning-and-testingfolder contains standalone sample code optimized for learning, experimenting, and testing (but not direct production usage).
Production deployment
If you want to deploy this repo in production, check out the following resources:
- examples/for-production folder: The
examples/for-productionfolder contains sample code optimized for direct usage in production. This is code from the Gruntwork Reference Architecture, and it shows you how we build an end-to-end, integrated tech stack on top of the Gruntwork Service Catalog.
Sample Usage
- Terraform
- Terragrunt
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S AURORA MODULE
#
# NOTE: This module uses some sensitive variables marked inline with "# SENSITIVE".
# When using values other than defaults for these variables, set them through environment variables or
# another secure method.
#
# ------------------------------------------------------------------------------------------------------
module "aurora" {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/data-stores/aurora?ref=v2.11.1"
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# The list of IDs of the subnets in which to deploy Aurora. The list must only
# contain subnets in var.vpc_id.
aurora_subnet_ids = <list(string)>
# The name used to namespace all the Aurora resources created by these
# templates, including the cluster and cluster instances (e.g. drupaldb). Must
# be unique in this region. Must be a lowercase string.
name = <string>
# The ID of the VPC in which to deploy Aurora.
vpc_id = <string>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and
# disk space usage) should send notifications. Also used for the alarms if the
# share snapshot backup job fails.
alarms_sns_topic_arns = []
# The list of network CIDR blocks to allow network access to Aurora from. One
# of var.allow_connections_from_cidr_blocks or
# var.allow_connections_from_security_groups must be specified for the
# database to be reachable.
allow_connections_from_cidr_blocks = []
# The list of IPv6 CIDR blocks to allow network access to Aurora from for
# dual-stack configurations. In the standard Gruntwork VPC setup with
# dual-stack enabled, these should be the IPv6 CIDR blocks of the private app
# subnets, plus the private subnets in the mgmt VPC.
allow_connections_from_ipv6_cidr_blocks = []
# The list of IDs or Security Groups to allow network access to Aurora from.
# All security groups must either be in the VPC specified by var.vpc_id, or a
# peered VPC with the VPC specified by var.vpc_id. One of
# var.allow_connections_from_cidr_blocks or
# var.allow_connections_from_security_groups must be specified for the
# database to be reachable.
allow_connections_from_security_groups = []
# Enable to allow major engine version upgrades when changing engine versions.
allow_major_version_upgrade = false
# Specifies whether any cluster modifications are applied immediately, or
# during the next maintenance window. Note that cluster modifications may
# cause degraded performance or downtime.
apply_immediately = false
# Configure the auto minor version upgrade behavior. This is applied to the
# cluster instances and indicates if the automatic minor version upgrade of
# the engine is allowed. Default value is true.
auto_minor_version_upgrade = true
# The amount of time in minutes before a backup job is canceled if it does not
# complete successfully. Maps to the backup plan rule's completion_window.
# Must be at least 60 minutes greater than var.backup_start_window. If null,
# AWS Backup uses its default.
backup_completion_window = null
# The number of days to retain recovery points in the destination backup vault
# before automatic deletion. Only used if var.backup_destination_vault_arn is
# set.
backup_destination_retention_days = 90
# The ARN of a destination backup vault for cross-account or cross-region
# copies. If null, no cross-account copy is configured.
backup_destination_vault_arn = null
# A map of tags to assign to the recovery points (backups) created by the
# backup plan rule. If null, no recovery point tags are applied.
backup_recovery_point_tags = null
# How many days to keep backup snapshots around before cleaning them up. Max:
# 35
backup_retention_period = 30
# A CRON expression specifying when AWS Backup should run the backup job (e.g.
# cron(0 0 * * ? *) for daily at midnight UTC). Required if var.enable_backup
# is true.
backup_schedule = null
# The name of the IAM service role for AWS Backup. Defaults to
# '<var.name>-backup-service-role' if not specified.
backup_service_role_name = null
# The number of days to retain recovery points in the source backup vault
# before automatic deletion.
backup_source_retention_days = 30
# The amount of time in minutes before a backup job is canceled if it does not
# start successfully. Maps to the backup plan rule's start_window. If null,
# AWS Backup uses its default.
backup_start_window = null
# The ARN of a KMS key used to encrypt the backup vault. If null, the default
# AWS Backup encryption will be used.
backup_vault_kms_key_arn = null
# The name of the AWS Backup vault to create. Defaults to
# '<var.name>-backup-vault' if not specified.
backup_vault_name = null
# An optional vault access policy to attach to the backup vault. Useful for
# granting cross-account access. Set to null to skip. See the backup-vault
# module for the expected structure.
backup_vault_policy = null
# The Certificate Authority (CA) certificate bundle to use on the Aurora DB
# instances. Possible values: rds-ca-2019 (default if nothing is specified),
# rds-ca-rsa2048-g1, rds-ca-rsa4096-g1, rds-ca-ecc384-g1.
ca_cert_identifier = null
# List of IAM role ARNs to attach to the cluster. Be sure these roles exists.
# They will not be created here. Serverless aurora does not support attaching
# IAM roles.
cluster_iam_roles = []
# The interval, in seconds, between points when Enhanced Monitoring metrics
# are collected for the cluster instances. To disable collecting Enhanced
# Monitoring metrics, specify 0. Allowed values: 0, 1, 5, 15, 30, 60. Enhanced
# Monitoring metrics are useful when you want to see how different processes
# or threads on a DB instance use the CPU.
cluster_monitoring_interval = null
# Specifies whether cluster level Performance Insights is enabled or not. On
# Aurora MySQL, Performance Insights is not supported on db.t2 or db.t3 DB
# instance classes.
cluster_performance_insights_enabled = false
# The ARN for the KMS key to encrypt cluster level Performance Insights data.
cluster_performance_insights_kms_key_id = null
# Specifies the amount of time to retain cluster level Performance Insights
# data for. Defaults to 7 days if Performance Insights are enabled. Valid
# values are 7, month * 31 (where month is a number of months from 1-23), and
# 731.
cluster_performance_insights_retention_period = null
# Copy all the Aurora cluster tags to snapshots. Default is false.
copy_tags_to_snapshot = false
# Set to true if you want a DNS record automatically created and pointed at
# the RDS endpoints.
create_route53_entry = false
# A map of custom tags to apply to the RDS cluster and all associated
# resources created for it. The key is the tag name and the value is the tag
# value.
custom_tags = {}
# Parameters for the cpu usage widget to output for use in a CloudWatch
# dashboard.
dashboard_cpu_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the database connections widget to output for use in a
# CloudWatch dashboard.
dashboard_db_connections_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the available disk space widget to output for use in a
# CloudWatch dashboard.
dashboard_disk_space_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the available memory widget to output for use in a CloudWatch
# dashboard.
dashboard_memory_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the read latency widget to output for use in a CloudWatch
# dashboard.
dashboard_read_latency_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the read latency widget to output for use in a CloudWatch
# dashboard.
dashboard_write_latency_widget_parameters = {"height":6,"period":60,"width":8}
# The mode of Database Insights to enable for the DB cluster. Valid options
# are 'standard' or 'advanced'. When setting this to 'advanced' then
# cluster_performance_insights_enabled must be set to true and
# 'cluster_performance_insights_retention_period' set to at least 465 days.
database_insights_mode = null
# Configure a custom parameter group for the RDS DB cluster. This will create
# a new parameter group with the given parameters. When null, the database
# will be launched with the default parameter group. Mutually exclusive with
# var.db_cluster_custom_parameter_group_name, which attaches a pre-existing
# parameter group instead.
db_cluster_custom_parameter_group = null
# Name of a pre-existing DB cluster parameter group to associate with the RDS
# cluster. Use this when you want to manage the parameter group outside of
# this module. Mutually exclusive with var.db_cluster_custom_parameter_group.
db_cluster_custom_parameter_group_name = null
# The friendly name or ARN of an AWS Secrets Manager secret that contains
# database configuration information in the format outlined by this document:
# https://docs.aws.amazon.com/secretsmanager/latest/userguide/best-practices.html.
# The engine, username, password, dbname, and port fields must be included in
# the JSON. Note that even with this precaution, this information will be
# stored in plaintext in the Terraform state file! See the following blog post
# for more details:
# https://blog.gruntwork.io/a-comprehensive-guide-to-managing-secrets-in-your-terraform-code-1d586955ace1.
# If you do not wish to use Secrets Manager, leave this as null, and use the
# master_username, master_password, db_name, engine, and port variables.
db_config_secrets_manager_id = null
# Configure a custom parameter group for the RDS DB Instance. This will create
# a new parameter group with the given parameters. When null, the database
# will be launched with the default parameter group. Mutually exclusive with
# var.db_instance_custom_parameter_group_name, which attaches a pre-existing
# parameter group instead.
db_instance_custom_parameter_group = null
# Name of a pre-existing DB parameter group to associate with the RDS DB
# instances. Use this when you want to manage the parameter group outside of
# this module. Mutually exclusive with var.db_instance_custom_parameter_group.
db_instance_custom_parameter_group_name = null
# The name for your database of up to 8 alpha-numeric characters. If you do
# not provide a name, Amazon RDS will not create a database in the DB cluster
# you are creating. This can also be provided via AWS Secrets Manager. See the
# description of db_config_secrets_manager_id. A value here overrides the
# value in db_config_secrets_manager_id.
db_name = null
# If true, delete all automated backups when the DB cluster is deleted. If
# false, automated backups are retained until the retention period expires.
# Defaults to true.
delete_automated_backups = null
# If set to true, create an AWS Backup vault and plan to periodically back up
# the Aurora DB. Supports optional cross-account copy via
# var.backup_destination_vault_arn.
enable_backup = false
# Set to true to enable several basic CloudWatch alarms around CPU usage,
# memory usage, and disk space usage. If set to true, make sure to specify SNS
# topics to send notifications to using var.alarms_sns_topic_arn.
enable_cloudwatch_alarms = true
# Enable deletion protection on the database instance. If this is enabled, the
# database cannot be deleted.
enable_deletion_protection = false
# Whether to enable global write forwarding on this Aurora cluster. When
# enabled on a secondary cluster in a global database, write SQL statements
# are forwarded to the primary cluster. Only applies to secondary clusters;
# setting this on the primary cluster has no effect. Supported on Aurora MySQL
# version 2.08.1+. See
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-write-forwarding.html
enable_global_write_forwarding = null
# If true, enables the HTTP endpoint used for Data API. Only valid when
# engine_mode is set to serverless.
enable_http_endpoint = null
# Set to true to enable alarms related to performance, such as read and write
# latency alarms. Set to false to disable those alarms if you aren't sure what
# would be reasonable perf numbers for your RDS set up or if those numbers are
# too unpredictable.
enable_perf_alarms = true
# If non-empty, the Aurora cluster will export the specified logs to
# Cloudwatch. Must be zero or more of: audit, error, general and slowquery
enabled_cloudwatch_logs_exports = []
# The name of the database engine to be used for this DB cluster. Valid
# Values: aurora (for MySQL 5.6-compatible Aurora), aurora-mysql (for MySQL
# 5.7-compatible Aurora), and aurora-postgresql. This can also be provided via
# AWS Secrets Manager. See the description of db_config_secrets_manager_id. A
# value here overrides the value in db_config_secrets_manager_id.
engine = null
# The DB engine mode of the DB cluster: either provisioned or serverless. Note
# that serverless (v1) is deprecated and no longer available for new clusters.
# For Aurora Serverless v2, use provisioned with
# scaling_configuration_min_capacity_V2 and
# scaling_configuration_max_capacity_V2.
engine_mode = "provisioned"
# The Amazon Aurora DB engine version for the selected engine and engine_mode.
# Note: Starting with Aurora MySQL 2.03.2, Aurora engine versions have the
# following syntax <mysql-major-version>.mysql_aurora.<aurora-mysql-version>.
# e.g. 5.7.mysql_aurora.2.08.1.
engine_version = null
# Global cluster identifier when creating the global secondary cluster.
global_cluster_identifier = null
# The period, in seconds, over which to measure the CPU utilization
# percentage.
high_cpu_utilization_period = 60
# Trigger an alarm if the DB instance has a CPU utilization percentage above
# this threshold.
high_cpu_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_cpu_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the read latency.
high_read_latency_period = 60
# Trigger an alarm if the DB instance read latency (average amount of time
# taken per disk I/O operation), in seconds, is above this threshold.
high_read_latency_threshold = 5
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_read_latency_treat_missing_data = "missing"
# The period, in seconds, over which to measure the write latency.
high_write_latency_period = 60
# Trigger an alarm if the DB instance write latency (average amount of time
# taken per disk I/O operation), in seconds, is above this threshold.
high_write_latency_threshold = 5
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_write_latency_treat_missing_data = "missing"
# The ID of the hosted zone in which to write DNS records
hosted_zone_id = null
# Specifies whether mappings of AWS Identity and Access Management (IAM)
# accounts to database accounts is enabled. Disabled by default.
iam_database_authentication_enabled = false
# The number of DB instances, including the primary, to run in the RDS
# cluster. Only used when var.engine_mode is set to provisioned.
instance_count = 1
# The instance type to use for the db (e.g. db.r3.large). Only used when
# var.engine_mode is set to provisioned.
instance_type = "db.t3.medium"
# The ARN of a KMS key that should be used to encrypt data on disk. Only used
# if var.storage_encrypted is true. If you leave this null, the default RDS
# KMS key for the account will be used.
kms_key_arn = null
# The period, in seconds, over which to measure the available free disk space.
low_disk_space_available_period = 60
# Trigger an alarm if the amount of disk space, in Bytes, on the DB instance
# drops below this threshold.
low_disk_space_available_threshold = 1000000000
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
low_disk_space_available_treat_missing_data = "missing"
# The period, in seconds, over which to measure the available free memory.
low_memory_available_period = 60
# Trigger an alarm if the amount of free memory, in Bytes, on the DB instance
# drops below this threshold.
low_memory_available_threshold = 100000000
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
low_memory_available_treat_missing_data = "missing"
# Set to true to allow RDS to manage the master user password in Secrets
# Manager. Cannot be set if password is provided.
manage_master_user_password = null
# The value to use for the master password of the database. This can also be
# provided via AWS Secrets Manager. See the description of
# db_config_secrets_manager_id. A value here overrides the value in
# db_config_secrets_manager_id.
master_password = null # SENSITIVE
# The value to use for the master username of the database. This can also be
# provided via AWS Secrets Manager. See the description of
# db_config_secrets_manager_id. A value here overrides the value in
# db_config_secrets_manager_id.
master_username = null
# Specifies whether Performance Insights is enabled or not. On Aurora MySQL,
# Performance Insights is not supported on db.t2 or db.t3 DB instance classes.
performance_insights_enabled = false
# The ARN for the KMS key to encrypt Performance Insights data.
performance_insights_kms_key_id = null
# The amount of time in days to retain Performance Insights data. Either 7 (7
# days) or 731 (2 years). When specifying
# performance_insights_retention_period, performance_insights_enabled needs to
# be set to true. Defaults to 7.
performance_insights_retention_period = null
# The port the DB will listen on (e.g. 3306). This can also be provided via
# AWS Secrets Manager. See the description of db_config_secrets_manager_id. A
# value here overrides the value in db_config_secrets_manager_id.
port = null
# The daily time range during which automated backups are created (e.g.
# 04:00-09:00). Time zone is UTC. Performance may be degraded while a backup
# runs.
preferred_backup_window = "06:00-07:00"
# The weekly day and time range during which cluster maintenance can occur
# (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or
# there may even be a downtime during maintenance windows.
preferred_maintenance_window = "sun:07:00-sun:08:00"
# The domain name to create a route 53 record for the primary endpoint of the
# RDS database.
primary_domain_name = null
# If you wish to make your database accessible from the public Internet, set
# this flag to true (WARNING: NOT RECOMMENDED FOR REGULAR USAGE!!). The
# default is false, which means the database is only accessible from within
# the VPC, which is much more secure. This flag MUST be false for serverless
# mode.
publicly_accessible = false
# The domain name to create a route 53 record for the reader endpoint of the
# RDS database. Note that Aurora Serverless does not have reader endpoints, so
# this option is ignored when engine_mode is set to serverless.
reader_domain_name = null
# ARN of a source DB cluster or DB instance if this DB cluster is to be
# created as a Read Replica.
replication_source_identifier = null
# If non-empty, the Aurora cluster will be restored from the given source
# cluster using the latest restorable time. Can only be used if
# snapshot_identifier is null. For more information see
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_PIT.html
restore_source_cluster_identifier = null
# Only used if 'restore_source_cluster_identifier' is non-empty. Date and time
# in UTC format to restore the database cluster to (e.g,
# 2009-09-07T23:45:00Z). When null, the latest restorable time will be used.
restore_to_time = null
# Only used if 'restore_source_cluster_identifier' is non-empty. Type of
# restore to be performed. Valid options are 'full-copy' and 'copy-on-write'.
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html
restore_type = null
# Whether to enable automatic pause. A DB cluster can be paused only when it's
# idle (it has no connections). If a DB cluster is paused for more than seven
# days, the DB cluster might be backed up with a snapshot. In this case, the
# DB cluster is restored when there is a request to connect to it. Only used
# when var.engine_mode is set to serverless.
scaling_configuration_auto_pause = true
# The maximum capacity. The maximum capacity must be greater than or equal to
# the minimum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128,
# and 256. Only used when var.engine_mode is set to serverless.
scaling_configuration_max_capacity = 256
scaling_configuration_max_capacity_V2 = null
# The minimum capacity. The minimum capacity must be lesser than or equal to
# the maximum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128,
# and 256. Only used when var.engine_mode is set to serverless.
scaling_configuration_min_capacity = 2
scaling_configuration_min_capacity_V2 = null
# The time, in seconds, before an Aurora DB cluster in serverless mode is
# paused. Valid values are 300 through 86400. Only used when var.engine_mode
# is set to serverless.
scaling_configuration_seconds_until_auto_pause = 300
# Determines whether a final DB snapshot is created before the DB instance is
# deleted. Be very careful setting this to true; if you do, and you delete
# this DB instance, you will not have any backups of the data! You almost
# never want to set this to true, unless you are doing automated or manual
# testing.
skip_final_snapshot = false
# If non-null, the RDS Instance will be restored from the given Snapshot ID.
# This is the Snapshot ID you'd find in the RDS console, e.g:
# rds:production-2015-06-26-06-05.
snapshot_identifier = null
# Specifies whether the DB cluster uses encryption for data at rest in the
# underlying storage for the DB, its automated backups, Read Replicas, and
# snapshots. Uses the default aws/rds key in KMS.
storage_encrypted = true
# Trigger an alarm if the number of connections to the DB instance goes above
# this threshold.
too_many_db_connections_threshold = null
}
# ------------------------------------------------------------------------------------------------------
# DEPLOY GRUNTWORK'S AURORA MODULE
#
# NOTE: This module uses some sensitive variables marked inline with "# SENSITIVE".
# When using values other than defaults for these variables, set them through environment variables or
# another secure method.
#
# ------------------------------------------------------------------------------------------------------
terraform {
source = "git::git@github.com:gruntwork-io/terraform-aws-service-catalog.git//modules/data-stores/aurora?ref=v2.11.1"
}
inputs = {
# ----------------------------------------------------------------------------------------------------
# REQUIRED VARIABLES
# ----------------------------------------------------------------------------------------------------
# The list of IDs of the subnets in which to deploy Aurora. The list must only
# contain subnets in var.vpc_id.
aurora_subnet_ids = <list(string)>
# The name used to namespace all the Aurora resources created by these
# templates, including the cluster and cluster instances (e.g. drupaldb). Must
# be unique in this region. Must be a lowercase string.
name = <string>
# The ID of the VPC in which to deploy Aurora.
vpc_id = <string>
# ----------------------------------------------------------------------------------------------------
# OPTIONAL VARIABLES
# ----------------------------------------------------------------------------------------------------
# The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and
# disk space usage) should send notifications. Also used for the alarms if the
# share snapshot backup job fails.
alarms_sns_topic_arns = []
# The list of network CIDR blocks to allow network access to Aurora from. One
# of var.allow_connections_from_cidr_blocks or
# var.allow_connections_from_security_groups must be specified for the
# database to be reachable.
allow_connections_from_cidr_blocks = []
# The list of IPv6 CIDR blocks to allow network access to Aurora from for
# dual-stack configurations. In the standard Gruntwork VPC setup with
# dual-stack enabled, these should be the IPv6 CIDR blocks of the private app
# subnets, plus the private subnets in the mgmt VPC.
allow_connections_from_ipv6_cidr_blocks = []
# The list of IDs or Security Groups to allow network access to Aurora from.
# All security groups must either be in the VPC specified by var.vpc_id, or a
# peered VPC with the VPC specified by var.vpc_id. One of
# var.allow_connections_from_cidr_blocks or
# var.allow_connections_from_security_groups must be specified for the
# database to be reachable.
allow_connections_from_security_groups = []
# Enable to allow major engine version upgrades when changing engine versions.
allow_major_version_upgrade = false
# Specifies whether any cluster modifications are applied immediately, or
# during the next maintenance window. Note that cluster modifications may
# cause degraded performance or downtime.
apply_immediately = false
# Configure the auto minor version upgrade behavior. This is applied to the
# cluster instances and indicates if the automatic minor version upgrade of
# the engine is allowed. Default value is true.
auto_minor_version_upgrade = true
# The amount of time in minutes before a backup job is canceled if it does not
# complete successfully. Maps to the backup plan rule's completion_window.
# Must be at least 60 minutes greater than var.backup_start_window. If null,
# AWS Backup uses its default.
backup_completion_window = null
# The number of days to retain recovery points in the destination backup vault
# before automatic deletion. Only used if var.backup_destination_vault_arn is
# set.
backup_destination_retention_days = 90
# The ARN of a destination backup vault for cross-account or cross-region
# copies. If null, no cross-account copy is configured.
backup_destination_vault_arn = null
# A map of tags to assign to the recovery points (backups) created by the
# backup plan rule. If null, no recovery point tags are applied.
backup_recovery_point_tags = null
# How many days to keep backup snapshots around before cleaning them up. Max:
# 35
backup_retention_period = 30
# A CRON expression specifying when AWS Backup should run the backup job (e.g.
# cron(0 0 * * ? *) for daily at midnight UTC). Required if var.enable_backup
# is true.
backup_schedule = null
# The name of the IAM service role for AWS Backup. Defaults to
# '<var.name>-backup-service-role' if not specified.
backup_service_role_name = null
# The number of days to retain recovery points in the source backup vault
# before automatic deletion.
backup_source_retention_days = 30
# The amount of time in minutes before a backup job is canceled if it does not
# start successfully. Maps to the backup plan rule's start_window. If null,
# AWS Backup uses its default.
backup_start_window = null
# The ARN of a KMS key used to encrypt the backup vault. If null, the default
# AWS Backup encryption will be used.
backup_vault_kms_key_arn = null
# The name of the AWS Backup vault to create. Defaults to
# '<var.name>-backup-vault' if not specified.
backup_vault_name = null
# An optional vault access policy to attach to the backup vault. Useful for
# granting cross-account access. Set to null to skip. See the backup-vault
# module for the expected structure.
backup_vault_policy = null
# The Certificate Authority (CA) certificate bundle to use on the Aurora DB
# instances. Possible values: rds-ca-2019 (default if nothing is specified),
# rds-ca-rsa2048-g1, rds-ca-rsa4096-g1, rds-ca-ecc384-g1.
ca_cert_identifier = null
# List of IAM role ARNs to attach to the cluster. Be sure these roles exists.
# They will not be created here. Serverless aurora does not support attaching
# IAM roles.
cluster_iam_roles = []
# The interval, in seconds, between points when Enhanced Monitoring metrics
# are collected for the cluster instances. To disable collecting Enhanced
# Monitoring metrics, specify 0. Allowed values: 0, 1, 5, 15, 30, 60. Enhanced
# Monitoring metrics are useful when you want to see how different processes
# or threads on a DB instance use the CPU.
cluster_monitoring_interval = null
# Specifies whether cluster level Performance Insights is enabled or not. On
# Aurora MySQL, Performance Insights is not supported on db.t2 or db.t3 DB
# instance classes.
cluster_performance_insights_enabled = false
# The ARN for the KMS key to encrypt cluster level Performance Insights data.
cluster_performance_insights_kms_key_id = null
# Specifies the amount of time to retain cluster level Performance Insights
# data for. Defaults to 7 days if Performance Insights are enabled. Valid
# values are 7, month * 31 (where month is a number of months from 1-23), and
# 731.
cluster_performance_insights_retention_period = null
# Copy all the Aurora cluster tags to snapshots. Default is false.
copy_tags_to_snapshot = false
# Set to true if you want a DNS record automatically created and pointed at
# the RDS endpoints.
create_route53_entry = false
# A map of custom tags to apply to the RDS cluster and all associated
# resources created for it. The key is the tag name and the value is the tag
# value.
custom_tags = {}
# Parameters for the cpu usage widget to output for use in a CloudWatch
# dashboard.
dashboard_cpu_usage_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the database connections widget to output for use in a
# CloudWatch dashboard.
dashboard_db_connections_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the available disk space widget to output for use in a
# CloudWatch dashboard.
dashboard_disk_space_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the available memory widget to output for use in a CloudWatch
# dashboard.
dashboard_memory_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the read latency widget to output for use in a CloudWatch
# dashboard.
dashboard_read_latency_widget_parameters = {"height":6,"period":60,"width":8}
# Parameters for the read latency widget to output for use in a CloudWatch
# dashboard.
dashboard_write_latency_widget_parameters = {"height":6,"period":60,"width":8}
# The mode of Database Insights to enable for the DB cluster. Valid options
# are 'standard' or 'advanced'. When setting this to 'advanced' then
# cluster_performance_insights_enabled must be set to true and
# 'cluster_performance_insights_retention_period' set to at least 465 days.
database_insights_mode = null
# Configure a custom parameter group for the RDS DB cluster. This will create
# a new parameter group with the given parameters. When null, the database
# will be launched with the default parameter group. Mutually exclusive with
# var.db_cluster_custom_parameter_group_name, which attaches a pre-existing
# parameter group instead.
db_cluster_custom_parameter_group = null
# Name of a pre-existing DB cluster parameter group to associate with the RDS
# cluster. Use this when you want to manage the parameter group outside of
# this module. Mutually exclusive with var.db_cluster_custom_parameter_group.
db_cluster_custom_parameter_group_name = null
# The friendly name or ARN of an AWS Secrets Manager secret that contains
# database configuration information in the format outlined by this document:
# https://docs.aws.amazon.com/secretsmanager/latest/userguide/best-practices.html.
# The engine, username, password, dbname, and port fields must be included in
# the JSON. Note that even with this precaution, this information will be
# stored in plaintext in the Terraform state file! See the following blog post
# for more details:
# https://blog.gruntwork.io/a-comprehensive-guide-to-managing-secrets-in-your-terraform-code-1d586955ace1.
# If you do not wish to use Secrets Manager, leave this as null, and use the
# master_username, master_password, db_name, engine, and port variables.
db_config_secrets_manager_id = null
# Configure a custom parameter group for the RDS DB Instance. This will create
# a new parameter group with the given parameters. When null, the database
# will be launched with the default parameter group. Mutually exclusive with
# var.db_instance_custom_parameter_group_name, which attaches a pre-existing
# parameter group instead.
db_instance_custom_parameter_group = null
# Name of a pre-existing DB parameter group to associate with the RDS DB
# instances. Use this when you want to manage the parameter group outside of
# this module. Mutually exclusive with var.db_instance_custom_parameter_group.
db_instance_custom_parameter_group_name = null
# The name for your database of up to 8 alpha-numeric characters. If you do
# not provide a name, Amazon RDS will not create a database in the DB cluster
# you are creating. This can also be provided via AWS Secrets Manager. See the
# description of db_config_secrets_manager_id. A value here overrides the
# value in db_config_secrets_manager_id.
db_name = null
# If true, delete all automated backups when the DB cluster is deleted. If
# false, automated backups are retained until the retention period expires.
# Defaults to true.
delete_automated_backups = null
# If set to true, create an AWS Backup vault and plan to periodically back up
# the Aurora DB. Supports optional cross-account copy via
# var.backup_destination_vault_arn.
enable_backup = false
# Set to true to enable several basic CloudWatch alarms around CPU usage,
# memory usage, and disk space usage. If set to true, make sure to specify SNS
# topics to send notifications to using var.alarms_sns_topic_arn.
enable_cloudwatch_alarms = true
# Enable deletion protection on the database instance. If this is enabled, the
# database cannot be deleted.
enable_deletion_protection = false
# Whether to enable global write forwarding on this Aurora cluster. When
# enabled on a secondary cluster in a global database, write SQL statements
# are forwarded to the primary cluster. Only applies to secondary clusters;
# setting this on the primary cluster has no effect. Supported on Aurora MySQL
# version 2.08.1+. See
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-write-forwarding.html
enable_global_write_forwarding = null
# If true, enables the HTTP endpoint used for Data API. Only valid when
# engine_mode is set to serverless.
enable_http_endpoint = null
# Set to true to enable alarms related to performance, such as read and write
# latency alarms. Set to false to disable those alarms if you aren't sure what
# would be reasonable perf numbers for your RDS set up or if those numbers are
# too unpredictable.
enable_perf_alarms = true
# If non-empty, the Aurora cluster will export the specified logs to
# Cloudwatch. Must be zero or more of: audit, error, general and slowquery
enabled_cloudwatch_logs_exports = []
# The name of the database engine to be used for this DB cluster. Valid
# Values: aurora (for MySQL 5.6-compatible Aurora), aurora-mysql (for MySQL
# 5.7-compatible Aurora), and aurora-postgresql. This can also be provided via
# AWS Secrets Manager. See the description of db_config_secrets_manager_id. A
# value here overrides the value in db_config_secrets_manager_id.
engine = null
# The DB engine mode of the DB cluster: either provisioned or serverless. Note
# that serverless (v1) is deprecated and no longer available for new clusters.
# For Aurora Serverless v2, use provisioned with
# scaling_configuration_min_capacity_V2 and
# scaling_configuration_max_capacity_V2.
engine_mode = "provisioned"
# The Amazon Aurora DB engine version for the selected engine and engine_mode.
# Note: Starting with Aurora MySQL 2.03.2, Aurora engine versions have the
# following syntax <mysql-major-version>.mysql_aurora.<aurora-mysql-version>.
# e.g. 5.7.mysql_aurora.2.08.1.
engine_version = null
# Global cluster identifier when creating the global secondary cluster.
global_cluster_identifier = null
# The period, in seconds, over which to measure the CPU utilization
# percentage.
high_cpu_utilization_period = 60
# Trigger an alarm if the DB instance has a CPU utilization percentage above
# this threshold.
high_cpu_utilization_threshold = 90
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_cpu_utilization_treat_missing_data = "missing"
# The period, in seconds, over which to measure the read latency.
high_read_latency_period = 60
# Trigger an alarm if the DB instance read latency (average amount of time
# taken per disk I/O operation), in seconds, is above this threshold.
high_read_latency_threshold = 5
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_read_latency_treat_missing_data = "missing"
# The period, in seconds, over which to measure the write latency.
high_write_latency_period = 60
# Trigger an alarm if the DB instance write latency (average amount of time
# taken per disk I/O operation), in seconds, is above this threshold.
high_write_latency_threshold = 5
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
high_write_latency_treat_missing_data = "missing"
# The ID of the hosted zone in which to write DNS records
hosted_zone_id = null
# Specifies whether mappings of AWS Identity and Access Management (IAM)
# accounts to database accounts is enabled. Disabled by default.
iam_database_authentication_enabled = false
# The number of DB instances, including the primary, to run in the RDS
# cluster. Only used when var.engine_mode is set to provisioned.
instance_count = 1
# The instance type to use for the db (e.g. db.r3.large). Only used when
# var.engine_mode is set to provisioned.
instance_type = "db.t3.medium"
# The ARN of a KMS key that should be used to encrypt data on disk. Only used
# if var.storage_encrypted is true. If you leave this null, the default RDS
# KMS key for the account will be used.
kms_key_arn = null
# The period, in seconds, over which to measure the available free disk space.
low_disk_space_available_period = 60
# Trigger an alarm if the amount of disk space, in Bytes, on the DB instance
# drops below this threshold.
low_disk_space_available_threshold = 1000000000
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
low_disk_space_available_treat_missing_data = "missing"
# The period, in seconds, over which to measure the available free memory.
low_memory_available_period = 60
# Trigger an alarm if the amount of free memory, in Bytes, on the DB instance
# drops below this threshold.
low_memory_available_threshold = 100000000
# Sets how this alarm should handle entering the INSUFFICIENT_DATA state.
# Based on
# https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data.
# Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
low_memory_available_treat_missing_data = "missing"
# Set to true to allow RDS to manage the master user password in Secrets
# Manager. Cannot be set if password is provided.
manage_master_user_password = null
# The value to use for the master password of the database. This can also be
# provided via AWS Secrets Manager. See the description of
# db_config_secrets_manager_id. A value here overrides the value in
# db_config_secrets_manager_id.
master_password = null # SENSITIVE
# The value to use for the master username of the database. This can also be
# provided via AWS Secrets Manager. See the description of
# db_config_secrets_manager_id. A value here overrides the value in
# db_config_secrets_manager_id.
master_username = null
# Specifies whether Performance Insights is enabled or not. On Aurora MySQL,
# Performance Insights is not supported on db.t2 or db.t3 DB instance classes.
performance_insights_enabled = false
# The ARN for the KMS key to encrypt Performance Insights data.
performance_insights_kms_key_id = null
# The amount of time in days to retain Performance Insights data. Either 7 (7
# days) or 731 (2 years). When specifying
# performance_insights_retention_period, performance_insights_enabled needs to
# be set to true. Defaults to 7.
performance_insights_retention_period = null
# The port the DB will listen on (e.g. 3306). This can also be provided via
# AWS Secrets Manager. See the description of db_config_secrets_manager_id. A
# value here overrides the value in db_config_secrets_manager_id.
port = null
# The daily time range during which automated backups are created (e.g.
# 04:00-09:00). Time zone is UTC. Performance may be degraded while a backup
# runs.
preferred_backup_window = "06:00-07:00"
# The weekly day and time range during which cluster maintenance can occur
# (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or
# there may even be a downtime during maintenance windows.
preferred_maintenance_window = "sun:07:00-sun:08:00"
# The domain name to create a route 53 record for the primary endpoint of the
# RDS database.
primary_domain_name = null
# If you wish to make your database accessible from the public Internet, set
# this flag to true (WARNING: NOT RECOMMENDED FOR REGULAR USAGE!!). The
# default is false, which means the database is only accessible from within
# the VPC, which is much more secure. This flag MUST be false for serverless
# mode.
publicly_accessible = false
# The domain name to create a route 53 record for the reader endpoint of the
# RDS database. Note that Aurora Serverless does not have reader endpoints, so
# this option is ignored when engine_mode is set to serverless.
reader_domain_name = null
# ARN of a source DB cluster or DB instance if this DB cluster is to be
# created as a Read Replica.
replication_source_identifier = null
# If non-empty, the Aurora cluster will be restored from the given source
# cluster using the latest restorable time. Can only be used if
# snapshot_identifier is null. For more information see
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_PIT.html
restore_source_cluster_identifier = null
# Only used if 'restore_source_cluster_identifier' is non-empty. Date and time
# in UTC format to restore the database cluster to (e.g,
# 2009-09-07T23:45:00Z). When null, the latest restorable time will be used.
restore_to_time = null
# Only used if 'restore_source_cluster_identifier' is non-empty. Type of
# restore to be performed. Valid options are 'full-copy' and 'copy-on-write'.
# https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html
restore_type = null
# Whether to enable automatic pause. A DB cluster can be paused only when it's
# idle (it has no connections). If a DB cluster is paused for more than seven
# days, the DB cluster might be backed up with a snapshot. In this case, the
# DB cluster is restored when there is a request to connect to it. Only used
# when var.engine_mode is set to serverless.
scaling_configuration_auto_pause = true
# The maximum capacity. The maximum capacity must be greater than or equal to
# the minimum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128,
# and 256. Only used when var.engine_mode is set to serverless.
scaling_configuration_max_capacity = 256
scaling_configuration_max_capacity_V2 = null
# The minimum capacity. The minimum capacity must be lesser than or equal to
# the maximum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128,
# and 256. Only used when var.engine_mode is set to serverless.
scaling_configuration_min_capacity = 2
scaling_configuration_min_capacity_V2 = null
# The time, in seconds, before an Aurora DB cluster in serverless mode is
# paused. Valid values are 300 through 86400. Only used when var.engine_mode
# is set to serverless.
scaling_configuration_seconds_until_auto_pause = 300
# Determines whether a final DB snapshot is created before the DB instance is
# deleted. Be very careful setting this to true; if you do, and you delete
# this DB instance, you will not have any backups of the data! You almost
# never want to set this to true, unless you are doing automated or manual
# testing.
skip_final_snapshot = false
# If non-null, the RDS Instance will be restored from the given Snapshot ID.
# This is the Snapshot ID you'd find in the RDS console, e.g:
# rds:production-2015-06-26-06-05.
snapshot_identifier = null
# Specifies whether the DB cluster uses encryption for data at rest in the
# underlying storage for the DB, its automated backups, Read Replicas, and
# snapshots. Uses the default aws/rds key in KMS.
storage_encrypted = true
# Trigger an alarm if the number of connections to the DB instance goes above
# this threshold.
too_many_db_connections_threshold = null
}
Reference
- Inputs
- Outputs
Required
aurora_subnet_idslist(string)The list of IDs of the subnets in which to deploy Aurora. The list must only contain subnets in vpc_id.
namestringThe name used to namespace all the Aurora resources created by these templates, including the cluster and cluster instances (e.g. drupaldb). Must be unique in this region. Must be a lowercase string.
vpc_idstringThe ID of the VPC in which to deploy Aurora.
Optional
alarms_sns_topic_arnslist(string)The ARNs of SNS topics where CloudWatch alarms (e.g., for CPU, memory, and disk space usage) should send notifications. Also used for the alarms if the share snapshot backup job fails.
[]allow_connections_from_cidr_blockslist(string)The list of network CIDR blocks to allow network access to Aurora from. One of allow_connections_from_cidr_blocks or allow_connections_from_security_groups must be specified for the database to be reachable.
[]allow_connections_from_ipv6_cidr_blockslist(string)The list of IPv6 CIDR blocks to allow network access to Aurora from for dual-stack configurations. In the standard Gruntwork VPC setup with dual-stack enabled, these should be the IPv6 CIDR blocks of the private app subnets, plus the private subnets in the mgmt VPC.
[]allow_connections_from_security_groupslist(string)The list of IDs or Security Groups to allow network access to Aurora from. All security groups must either be in the VPC specified by vpc_id, or a peered VPC with the VPC specified by vpc_id. One of allow_connections_from_cidr_blocks or allow_connections_from_security_groups must be specified for the database to be reachable.
[]Enable to allow major engine version upgrades when changing engine versions.
falseSpecifies whether any cluster modifications are applied immediately, or during the next maintenance window. Note that cluster modifications may cause degraded performance or downtime.
falseConfigure the auto minor version upgrade behavior. This is applied to the cluster instances and indicates if the automatic minor version upgrade of the engine is allowed. Default value is true.
truebackup_completion_windownumberThe amount of time in minutes before a backup job is canceled if it does not complete successfully. Maps to the backup plan rule's completion_window. Must be at least 60 minutes greater than backup_start_window. If null, AWS Backup uses its default.
nullThe number of days to retain recovery points in the destination backup vault before automatic deletion. Only used if backup_destination_vault_arn is set.
90The ARN of a destination backup vault for cross-account or cross-region copies. If null, no cross-account copy is configured.
nullbackup_recovery_point_tagsmap(string)A map of tags to assign to the recovery points (backups) created by the backup plan rule. If null, no recovery point tags are applied.
nullbackup_retention_periodnumberHow many days to keep backup snapshots around before cleaning them up. Max: 35
30backup_schedulestringA CRON expression specifying when AWS Backup should run the backup job (e.g. cron(0 0 * * ? *) for daily at midnight UTC). Required if enable_backup is true.
nullbackup_service_role_namestringThe name of the IAM service role for AWS Backup. Defaults to '<name>-backup-service-role' if not specified.
nullThe number of days to retain recovery points in the source backup vault before automatic deletion.
30backup_start_windownumberThe amount of time in minutes before a backup job is canceled if it does not start successfully. Maps to the backup plan rule's start_window. If null, AWS Backup uses its default.
nullbackup_vault_kms_key_arnstringThe ARN of a KMS key used to encrypt the backup vault. If null, the default AWS Backup encryption will be used.
nullbackup_vault_namestringThe name of the AWS Backup vault to create. Defaults to '<name>-backup-vault' if not specified.
nullAn optional vault access policy to attach to the backup vault. Useful for granting cross-account access. Set to null to skip. See the backup-vault module for the expected structure.
Any types represent complex values of variable type. For details, please consult `variables.tf` in the source repo.
nullca_cert_identifierstringThe Certificate Authority (CA) certificate bundle to use on the Aurora DB instances. Possible values: rds-ca-2019 (default if nothing is specified), rds-ca-rsa2048-g1, rds-ca-rsa4096-g1, rds-ca-ecc384-g1.
nullcluster_iam_roleslist(string)List of IAM role ARNs to attach to the cluster. Be sure these roles exists. They will not be created here. Serverless aurora does not support attaching IAM roles.
[]The interval, in seconds, between points when Enhanced Monitoring metrics are collected for the cluster instances. To disable collecting Enhanced Monitoring metrics, specify 0. Allowed values: 0, 1, 5, 15, 30, 60. Enhanced Monitoring metrics are useful when you want to see how different processes or threads on a DB instance use the CPU.
nullSpecifies whether cluster level Performance Insights is enabled or not. On Aurora MySQL, Performance Insights is not supported on db.t2 or db.t3 DB instance classes.
falseThe ARN for the KMS key to encrypt cluster level Performance Insights data.
nullSpecifies the amount of time to retain cluster level Performance Insights data for. Defaults to 7 days if Performance Insights are enabled. Valid values are 7, month * 31 (where month is a number of months from 1-23), and 731.
nullCopy all the Aurora cluster tags to snapshots. Default is false.
falseSet to true if you want a DNS record automatically created and pointed at the RDS endpoints.
falsecustom_tagsmap(string)A map of custom tags to apply to the RDS cluster and all associated resources created for it. The key is the tag name and the value is the tag value.
{}Parameters for the cpu usage widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the database connections widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the available disk space widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
dashboard_memory_widget_parametersobject(…)Parameters for the available memory widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the read latency widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
Parameters for the read latency widget to output for use in a CloudWatch dashboard.
object({
# The period in seconds for metrics to sample across.
period = number
# The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
# space.
width = number
height = number
})
{
height = 6,
period = 60,
width = 8
}
Details
The width and height of the widget in grid units in a 24 column grid. E.g., a value of 12 will take up half the
space.
database_insights_modestringThe mode of Database Insights to enable for the DB cluster. Valid options are 'standard' or 'advanced'. When setting this to 'advanced' then cluster_performance_insights_enabled must be set to true and 'cluster_performance_insights_retention_period' set to at least 465 days.
nulldb_cluster_custom_parameter_groupobject(…)Configure a custom parameter group for the RDS DB cluster. This will create a new parameter group with the given parameters. When null, the database will be launched with the default parameter group. Mutually exclusive with db_cluster_custom_parameter_group_name, which attaches a pre-existing parameter group instead.
object({
# Name of the parameter group to create
name = string
# The family of the DB cluster parameter group.
family = string
# The parameters to configure on the created parameter group.
parameters = list(object({
# Parameter name to configure.
name = string
# Vaue to set the parameter.
value = string
# When to apply the parameter. "immediate" or "pending-reboot".
apply_method = string
}))
})
nullDetails
The family of the DB cluster parameter group.
Details
The parameters to configure on the created parameter group.
Details
Vaue to set the parameter.
Details
When to apply the parameter. "immediate" or "pending-reboot".
Name of a pre-existing DB cluster parameter group to associate with the RDS cluster. Use this when you want to manage the parameter group outside of this module. Mutually exclusive with db_cluster_custom_parameter_group.
nullThe friendly name or ARN of an AWS Secrets Manager secret that contains database configuration information in the format outlined by this document: https://docs.aws.amazon.com/secretsmanager/latest/userguide/best-practices.html. The engine, username, password, dbname, and port fields must be included in the JSON. Note that even with this precaution, this information will be stored in plaintext in the Terraform state file! See the following blog post for more details: https://blog.gruntwork.io/a-comprehensive-guide-to-managing-secrets-in-your-terraform-code-1d586955ace1. If you do not wish to use Secrets Manager, leave this as null, and use the master_username, master_password, db_name, engine, and port variables.
nulldb_instance_custom_parameter_groupobject(…)Configure a custom parameter group for the RDS DB Instance. This will create a new parameter group with the given parameters. When null, the database will be launched with the default parameter group. Mutually exclusive with db_instance_custom_parameter_group_name, which attaches a pre-existing parameter group instead.
object({
# Name of the parameter group to create
name = string
# The family of the DB cluster parameter group.
family = string
# The parameters to configure on the created parameter group.
parameters = list(object({
# Parameter name to configure.
name = string
# Vaue to set the parameter.
value = string
# When to apply the parameter. "immediate" or "pending-reboot".
apply_method = string
}))
})
nullDetails
The family of the DB cluster parameter group.
Details
The parameters to configure on the created parameter group.
Details
Vaue to set the parameter.
Details
When to apply the parameter. "immediate" or "pending-reboot".
Name of a pre-existing DB parameter group to associate with the RDS DB instances. Use this when you want to manage the parameter group outside of this module. Mutually exclusive with db_instance_custom_parameter_group.
nulldb_namestringThe name for your database of up to 8 alpha-numeric characters. If you do not provide a name, Amazon RDS will not create a database in the DB cluster you are creating. This can also be provided via AWS Secrets Manager. See the description of db_config_secrets_manager_id. A value here overrides the value in db_config_secrets_manager_id.
nullIf true, delete all automated backups when the DB cluster is deleted. If false, automated backups are retained until the retention period expires. Defaults to true.
nullenable_backupboolIf set to true, create an AWS Backup vault and plan to periodically back up the Aurora DB. Supports optional cross-account copy via backup_destination_vault_arn.
falseSet to true to enable several basic CloudWatch alarms around CPU usage, memory usage, and disk space usage. If set to true, make sure to specify SNS topics to send notifications to using alarms_sns_topic_arn.
trueEnable deletion protection on the database instance. If this is enabled, the database cannot be deleted.
falseWhether to enable global write forwarding on this Aurora cluster. When enabled on a secondary cluster in a global database, write SQL statements are forwarded to the primary cluster. Only applies to secondary clusters; setting this on the primary cluster has no effect. Supported on Aurora MySQL version 2.08.1+. See https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-write-forwarding.html
nullIf true, enables the HTTP endpoint used for Data API. Only valid when engine_mode is set to serverless.
nullSet to true to enable alarms related to performance, such as read and write latency alarms. Set to false to disable those alarms if you aren't sure what would be reasonable perf numbers for your RDS set up or if those numbers are too unpredictable.
trueenabled_cloudwatch_logs_exportslist(string)If non-empty, the Aurora cluster will export the specified logs to Cloudwatch. Must be zero or more of: audit, error, general and slowquery
[]enginestringThe name of the database engine to be used for this DB cluster. Valid Values: aurora (for MySQL 5.6-compatible Aurora), aurora-mysql (for MySQL 5.7-compatible Aurora), and aurora-postgresql. This can also be provided via AWS Secrets Manager. See the description of db_config_secrets_manager_id. A value here overrides the value in db_config_secrets_manager_id.
nullengine_modestringThe DB engine mode of the DB cluster: either provisioned or serverless. Note that serverless (v1) is deprecated and no longer available for new clusters. For Aurora Serverless v2, use provisioned with scaling_configuration_min_capacity_V2 and scaling_configuration_max_capacity_V2.
"provisioned"engine_versionstringThe Amazon Aurora DB engine version for the selected engine and engine_mode. Note: Starting with Aurora MySQL 2.03.2, Aurora engine versions have the following syntax <mysql-major-version>.mysql_aurora.<aurora-mysql-version>. e.g. 5.7.mysql_aurora.2.08.1.
nullGlobal cluster identifier when creating the global secondary cluster.
nullThe period, in seconds, over which to measure the CPU utilization percentage.
60Trigger an alarm if the DB instance has a CPU utilization percentage above this threshold.
90Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"high_read_latency_periodnumberThe period, in seconds, over which to measure the read latency.
60Trigger an alarm if the DB instance read latency (average amount of time taken per disk I/O operation), in seconds, is above this threshold.
5Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"The period, in seconds, over which to measure the write latency.
60Trigger an alarm if the DB instance write latency (average amount of time taken per disk I/O operation), in seconds, is above this threshold.
5Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"hosted_zone_idstringThe ID of the hosted zone in which to write DNS records
nullSpecifies whether mappings of AWS Identity and Access Management (IAM) accounts to database accounts is enabled. Disabled by default.
falseinstance_countnumberThe number of DB instances, including the primary, to run in the RDS cluster. Only used when engine_mode is set to provisioned.
1instance_typestringThe instance type to use for the db (e.g. db.r3.large). Only used when engine_mode is set to provisioned.
"db.t3.medium"Details
See https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Aurora.Managing.html for the instance types supported by
Aurora
kms_key_arnstringThe ARN of a KMS key that should be used to encrypt data on disk. Only used if storage_encrypted is true. If you leave this null, the default RDS KMS key for the account will be used.
nullThe period, in seconds, over which to measure the available free disk space.
60Trigger an alarm if the amount of disk space, in Bytes, on the DB instance drops below this threshold.
1000000000Details
Default is 1GB (1 billion bytes)
Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"The period, in seconds, over which to measure the available free memory.
60Trigger an alarm if the amount of free memory, in Bytes, on the DB instance drops below this threshold.
100000000Details
Default is 100MB (100 million bytes)
Sets how this alarm should handle entering the INSUFFICIENT_DATA state. Based on https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/AlarmThatSendsEmail.html#alarms-and-missing-data. Must be one of: 'missing', 'ignore', 'breaching' or 'notBreaching'.
"missing"Set to true to allow RDS to manage the master user password in Secrets Manager. Cannot be set if password is provided.
nullmaster_passwordstringThe value to use for the master password of the database. This can also be provided via AWS Secrets Manager. See the description of db_config_secrets_manager_id. A value here overrides the value in db_config_secrets_manager_id.
nullmaster_usernamestringThe value to use for the master username of the database. This can also be provided via AWS Secrets Manager. See the description of db_config_secrets_manager_id. A value here overrides the value in db_config_secrets_manager_id.
nullSpecifies whether Performance Insights is enabled or not. On Aurora MySQL, Performance Insights is not supported on db.t2 or db.t3 DB instance classes.
falseThe ARN for the KMS key to encrypt Performance Insights data.
nullThe amount of time in days to retain Performance Insights data. Either 7 (7 days) or 731 (2 years). When specifying performance_insights_retention_period, performance_insights_enabled needs to be set to true. Defaults to 7.
nullportnumberThe port the DB will listen on (e.g. 3306). This can also be provided via AWS Secrets Manager. See the description of db_config_secrets_manager_id. A value here overrides the value in db_config_secrets_manager_id.
nullpreferred_backup_windowstringThe daily time range during which automated backups are created (e.g. 04:00-09:00). Time zone is UTC. Performance may be degraded while a backup runs.
"06:00-07:00"The weekly day and time range during which cluster maintenance can occur (e.g. wed:04:00-wed:04:30). Time zone is UTC. Performance may be degraded or there may even be a downtime during maintenance windows.
"sun:07:00-sun:08:00"primary_domain_namestringThe domain name to create a route 53 record for the primary endpoint of the RDS database.
nullIf you wish to make your database accessible from the public Internet, set this flag to true (WARNING: NOT RECOMMENDED FOR REGULAR USAGE!!). The default is false, which means the database is only accessible from within the VPC, which is much more secure. This flag MUST be false for serverless mode.
falsereader_domain_namestringThe domain name to create a route 53 record for the reader endpoint of the RDS database. Note that Aurora Serverless does not have reader endpoints, so this option is ignored when engine_mode is set to serverless.
nullARN of a source DB cluster or DB instance if this DB cluster is to be created as a Read Replica.
nullIf non-empty, the Aurora cluster will be restored from the given source cluster using the latest restorable time. Can only be used if snapshot_identifier is null. For more information see https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_PIT.html
nullrestore_to_timestringOnly used if 'restore_source_cluster_identifier' is non-empty. Date and time in UTC format to restore the database cluster to (e.g, 2009-09-07T23:45:00Z). When null, the latest restorable time will be used.
nullrestore_typestringOnly used if 'restore_source_cluster_identifier' is non-empty. Type of restore to be performed. Valid options are 'full-copy' and 'copy-on-write'. https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html
nullWhether to enable automatic pause. A DB cluster can be paused only when it's idle (it has no connections). If a DB cluster is paused for more than seven days, the DB cluster might be backed up with a snapshot. In this case, the DB cluster is restored when there is a request to connect to it. Only used when engine_mode is set to serverless.
trueThe maximum capacity. The maximum capacity must be greater than or equal to the minimum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128, and 256. Only used when engine_mode is set to serverless.
256nullThe minimum capacity. The minimum capacity must be lesser than or equal to the maximum capacity. Valid capacity values are 2, 4, 8, 16, 32, 64, 128, and 256. Only used when engine_mode is set to serverless.
2nullThe time, in seconds, before an Aurora DB cluster in serverless mode is paused. Valid values are 300 through 86400. Only used when engine_mode is set to serverless.
300Determines whether a final DB snapshot is created before the DB instance is deleted. Be very careful setting this to true; if you do, and you delete this DB instance, you will not have any backups of the data! You almost never want to set this to true, unless you are doing automated or manual testing.
falsesnapshot_identifierstringIf non-null, the RDS Instance will be restored from the given Snapshot ID. This is the Snapshot ID you'd find in the RDS console, e.g: rds:production-2015-06-26-06-05.
nullSpecifies whether the DB cluster uses encryption for data at rest in the underlying storage for the DB, its automated backups, Read Replicas, and snapshots. Uses the default aws/rds key in KMS.
trueTrigger an alarm if the number of connections to the DB instance goes above this threshold.
nullDetails
The max number of connections allowed by RDS depends a) the type of DB, b) the DB instance type, and c) the
use case, and it can vary from ~30 all the way up to 5,000, so we cannot pick a reasonable default here.
A list of all the CloudWatch Dashboard metric widgets available in this module.
A list of ARNs of the AWS Backup plans created. Only populated if enable_backup is true.
The ARN of the IAM service role used by AWS Backup.
A map of backup vault names to their ARNs. Only populated if enable_backup is true.
The ARN of the RDS Aurora cluster.
The ID of the RDS Aurora cluster (e.g TODO).
The ARN of master user secret. Only available when manage_master_user_password is set to true
The unique resource ID assigned to the cluster e.g. cluster-POBCBQUFQC56EBAAWXGFJ77GRU. This is useful for allowing database authentication via IAM.
A list of endpoints of the RDS instances that you can use to make requests to.
A CloudWatch Dashboard widget that graphs CPU usage (percentage) of the Aurora cluster.
A CloudWatch Dashboard widget that graphs the number of active database connections of the Aurora cluster.
A CloudWatch Dashboard widget that graphs available disk space (in bytes) on the Aurora cluster.
A CloudWatch Dashboard widget that graphs available memory (in bytes) on the Aurora cluster.
A CloudWatch Dashboard widget that graphs the average amount of time taken per disk I/O operation on reads.
A CloudWatch Dashboard widget that graphs the average amount of time taken per disk I/O operation on writes.
The port used by the RDS Aurora cluster for handling database connections.
The primary endpoint of the RDS Aurora cluster that you can use to make requests to.
The host portion of the Aurora endpoint. primary_endpoint is in the form '<host>:<port>', and this output returns just the host part.
A read-only endpoint for the Aurora cluster, automatically load-balanced across replicas.
ID of security group created by aurora module.